爬虫
requests
安装
pip install requests
主要方法
| 方法 | 说明 | |
|---|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 | requests.request(method, url, **kwargs) |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET | requests.get(url, params=None, **kwargs) |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD | requests.head(url, **kwargs) |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST | requests.post(url, data=None, json=None, **kwargs) |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT | requests.put(url, data=None, **kwargs) |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH | requests.patch(url, data=None, **kwargs) |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE | requests.delete(url, **kwargs) |
HTTP方法
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
方法参数
requests.request(method, url, **kwargs)
method : 请求方式,对应get/put/post等7种,例如:‘GET’
| 参数 | 说明 |
|---|---|
| params | 字典或字节序列,作为参数增加到url中 |
| data | 字典、字节序列或文件对象,作为Request的内容 |
| json | JSON格式的数据,作为Request的内容 |
| headers | 字典,HTTP定制头 |
| cookies | 字典或CookieJar,Request中的cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典类型,传输文件 |
| timeout | 设定超时时间,秒为单位 |
| proxies | 字典类型,设定访问代理服务器,可以增加登录认证 |
| allow_redirects | True/False,默认为True,重定向开关 |
| stream | True/False,默认为True,获取内容立即下载开关 |
| verify | True/False,默认为True,认证SSL证书开关 |
| cert | 本地SSL证书路径 |
data和json参数的区别:
F12观察浏览器的请求,如果数据是Request Payload则使用json参数,如果数据是Form Data则使用data参数。
当然对于python来说,参数的值都是字典类型的。
data与params参数的区别:
data用于post请求,params用于get请求。
Response对象
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
Requests异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
raise_for_status()
判断r.status_code是否等于200,如果不是200,产生异常requests.HTTPError
基本架构
1
2
3
4
5
6
7
8
def mm(url):
try:
req = requests.get(url, timeout=10)
req.raise_for_status() # status_code != 200 抛异常
req.encoding = req.apparent_encoding
return req.text
except Exception:
return 'wrong'
UA伪装
1
2
3
4
5
6
7
8
9
10
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
param = {'query':kw}
response = requests.get(url=url, params=param, headers=headers)
data = {'kw':word}
response = requests.post(url=url, data=data, headers=headers)
dic_obj = response.json() # 转json
保存图片
1
2
3
img_data = requests.get(url=url).content # 二进制内容
with open('./img.jpg','wb') as fp: # 保存图片
fp.write(img_data)
AJAX
AJAX 是在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页内容的技术,即网页实现异步更新。
查看网页ajax请求的内容:
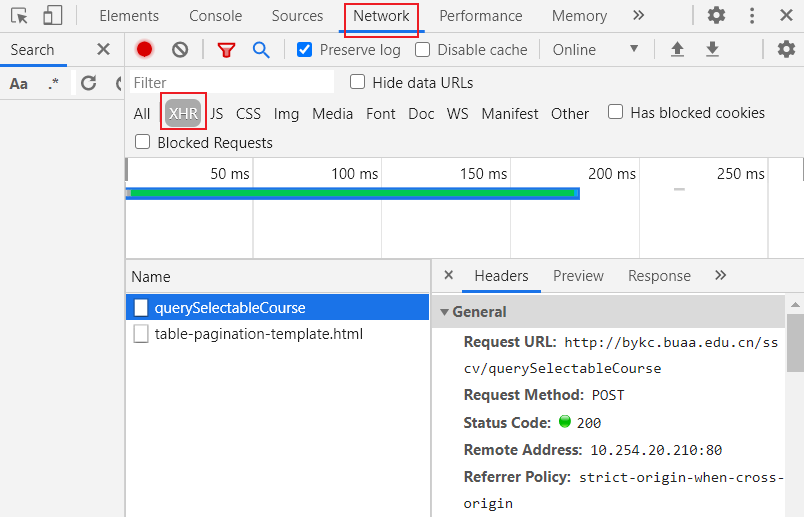
定位网页内容的方法:
右键“检查”,然后使用下图中的箭头,选中想要定位的内容即可。

re
raw string
raw string类型(原生字符串类型)
re库采用raw string类型表示正则表达式,表示为:r’text’
raw string是不包含对转义符再次转义的字符串
r’[1‐9]\d{5}’ 和 ‘[1‐9]\\d{5}’
主要方法
| 方法 | 说明 | 参数 |
|---|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 | re.search(pattern, string, flags=0) |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象【字符串跟正则完全匹配】 | re.match(pattern, string, flags=0) |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串。若正则中存在小括号,返回的子串是跟小括号内匹配的子串。多个小括号返回tuple的list | re.findall(pattern, string, flags=0) |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 | re.split(pattern, string, maxsplit=0, flags=0) |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 | re.finditer(pattern, string, flags=0) |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 | re.sub(pattern, repl, string, count=0, flags=0) |
参数
pattern : 正则表达式的字符串或原生字符串表示
string : 待匹配字符串
flags : 正则表达式使用时的控制标记,包括:
re.I re.IGNORECASE 忽略正则表达式的大小写,[A‐Z]能够匹配小写字符 re.M re.MULTILINE 正则表达式中的^操作符能够将给定字符串的每行当作匹配开始 re.S re.DOTALL 正则表达式中的.操作符能够匹配所有字符,包括换行
re.split(pattern, string, maxsplit=0, flags=0)
maxsplit: 最大分割数,剩余部分作为最后一个元素输出
re.sub(pattern, repl, string, count=0, flags=0)
repl : 替换匹配字符串的字符串
count : 匹配的最大替换次数
面向对象式写法
regex = re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象
1
2
regex = re.compile(r'[1‐9]\d{5}') # 先编译
match = regex.search('BIT 100081')
Match对象
Match对象是一次匹配的结果,包含匹配的很多信息
| 属性 | 说明 |
|---|---|
| .string | 待匹配的文本(原文本) |
| .re | 匹配时使用的patter对象(匹配用的正则式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
| .group(0) | 获得匹配后的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start(), .end()) |
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
match = re.search(r'[1-9]\d{5}', 'BIT 100081') # 查找匹配
print(type(match))
if match:
print(match.group(0)) # 匹配内容
for m in re.finditer(r'[1-9]\d{5}', 'BIT 100081 aaa111111'): # 返回第一个匹配的迭代
if m:
print(m.group(0))
re.findall(r'(\d{4})\w{3}', '3333www4444wwws5555www')
# ['3333', '4444', '5555']
re.findall(r'(\d{4})(\w{3})', '3333www4444wwws5555www')
# [('3333', 'www'), ('4444', 'www'), ('5555', 'www')]
正则入门
参考:https://deerchao.cn/tutorials/regex/regex.htm
元字符
| 字符 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
字符转义
使用\来取消字符的特殊意义。 \. \* \\ 等
例如:deerchao\.cn匹配deerchao.cn
字符重复
| 字符 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
字符集合
使用方括号 []
分支
| 使用符号 |
分组
使用小括号 ()
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (? |
匹配exp,并捕获文本到名称为name的组里,也可以写成(?’name’exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
反义
| 字符 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
贪婪与懒惰
| 字符 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
a.*?b匹配最短的,以a开始,以b结束的字符串。
如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)
匹配选项
| 字符 | 说明 |
|---|---|
| IgnoreCase(忽略大小写) | 匹配时不区分大小写。 |
| Multiline(多行模式) | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| ExplicitCapture(显式捕获) | 仅捕获已被显式命名的组。 |
beautifulsoup
安装
pip install beautifulsoup4
基本用法
bs4库将任何HTML输入都变成utf‐8编码
1
2
3
4
5
6
7
from bs4 import BeautifulSoup
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
fp = open('test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,’lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) | pip install html5lib |
基本元素
| 元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>…</p>的名字是’p’,格式: |
| Attributes | 标签的属性,字典形式组织,格式: |
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式: |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型,格式: |
1
2
3
4
5
6
7
8
# soup.<tagName> 返回第一个出现的tagName标签
soup.a # a标签 <a>..</a>
soup.a.name # 标签的名字
soup.a.attrs # 标签的属性,字典类型
soup.a.attrs['class'] # 属性的值
soup.a.get('href') # 属性的值
soup.a['class'] # 属性的值
soup.a.string # <>..</>之间的内容
获取标签间的文本
soup.text/soup.get_text():可以获取某一个标签中所有的文本内容,返回string类型
soup.string:只可以获取该标签下面直系的文本内容,返回NavigableString类型
| .string | .text | |
|---|---|---|
| <td>some text</td> | some text | some text |
| <td></td> | None | |
| <td><p>more text</p></td> | more text | more text |
| <td>even <p>more text</p></td> | None [1] | even more text |
[1] 因为有多个NavigableString,不知道输出哪一个
标签树的遍历
| 遍历 | 属性 | 说明 |
|---|---|---|
| 下行遍历 | .contents | 子节点的列表,将 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 | |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 | |
| 上行遍历 | .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 | |
| 平行遍历 | .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 | |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 | |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
平行遍历发生在同一个父节点下的各节点间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
soup.body.contents # 获得body的子节点的列表
for child in soup.body.children: # 儿子节点
print(child)
for child in soup.body.descendants: # 子孙节点
print(child)
soup.parent # 父标签 None
soup.title.parent # 父标签
for parent in soup.a.parents: # 父辈节点
if parent is None:
print(parent)
else:
print(parent.name)
soup.a.next_sibling # 下一个平行节点标签
soup.a.next_sibling.next_sibling
for s in soup.a.next_siblings:
print(s)
soup.a.previous_sibling # 上一个平行节点标签
soup.a.previous_sibling.previous_sibling
for s in soup.a.previous_siblings:
print(s)
find_all()
<>.find_all(name, attrs, recursive, string, **kwargs)
返回一个列表类型,存储查找的结果
name : 对标签名称tagName的检索字符串 可以传列表 [‘a’, ‘div’]
attrs: 对标签属性值的检索字符串,可标注属性检索
recursive: 是否对子孙全部检索,默认True
string: <>…</>中字符串区域的检索字符串
**<tag>(..) 等价于 <tag>.find_all(..) ** **soup(..) 等价于 soup.find_all(..) **
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 查找name
soup.find_all('a') # 查找标签a,返回列表
soup('a') # 等价写法
soup.find_all(['a', 'b']): # 传入标签名称列表
soup.find_all(True): # 返回全部标签
soup.find_all(re.compile('b')): # 查找标签名称符合正则的标签
# 标签<tag>也可以find_all
soup.body.find_all('a')
soup.body('a') # 等价写法
# 查找attrs
soup.find_all('p', 'course') # 不指定属性名,只要属性中带有course即可
soup.find_all(id='link1') # 指定属性名,查属性id=link1的标签
soup.find_all(id=re.compile('link')) # 指定属性名,查属性id符合正则的标签
soup.find_all(class_='link1') # 指定属性名,查属性class=link1的标签
# 参数recursive
soup.find_all('a', recursive=False) # False表示只查儿子
# 查找string
# 检索<>...</>之间的字符串,返回字符串的列表
soup.find_all(string='Basic Python')
soup(string='Basic Python') # 等价写法
soup.find_all(string=re.compile('python'))
| 函数 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_siblings() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
select()
传入选择器,返回标签列表
.name 表示选择class=name的标签
#name 表示选择id=name的标签
> 表示一个层次(a > b 表示a标签下的b标签) 空格表示多个层次
1
2
soup.select('.tang > ul > li > a') # >表示的是一个层级
soup.select('.tang > ul a') # 空格表示的多个层级
prettify()
.prettify()为HTML文本<>及其内容增加’\n’,格式化输出
1
2
soup.prettify() # 可以用于BeautifulSoup
soup.a.prettify() # 也可以用于Tag
xpath
安装
pip install lxml
基本用法
1
2
3
4
5
6
7
8
9
10
11
from lxml import etree
# 将本地的html文档中的源码数据加载到etree对象中
tree = etree.parse(filePath)
# 将从互联网上获取的源码数据加载到etree对象中
page_text = response.text
tree = etree.HTML(page_text)
# 返回的是列表
tree.xpath('xpath表达式')
xpath表达式
- xpath返回的是python的列表list
- 对于/text(),/@attrName,列表的内容是<class ‘lxml.etree._ElementUnicodeResult’>,就是str
- 对于定位元素的语句,列表的内容是<class ‘lxml.etree._Element’>,可以继续调用xpath使用局部解析
- xpath表达式中不能出现tbody标签
| 内容 | 例子 |
|---|---|
| /:表示的是从根节点开始定位。/表示的是一个层级 | tree.xpath(‘/html/body/div’) |
| //:表示的是多个层级。可以表示从任意位置开始定位。 | tree.xpath(‘/html//div’) tree.xpath(‘//div’) |
| 属性定位:tag[@attrName=”attrValue”] | tree.xpath(‘//div[@class=”song”]’) |
| 索引定位:tag[n] 索引是从1开始的。 | tree.xpath(‘//div[@class=”tang”]//li[5]’) |
| 取文本:/text() 获取的是标签中直系的文本内容;//text() 标签中非直系的文本内容(所有的文本内容) | tree.xpath(‘//div[@class=”tang”]//text()’) |
| 取属性:/@attrName | tree.xpath(‘//div[@class=”song”]/img/@src’) |
| 局部解析:相对于某个标签继续解析,使用./ | li.xpath(‘./div[2]/h2/a/text()’) a.xpath(‘./text()’) |
| 或关系 | | tree.xpath(‘./a[2]/b/text() | ./a[2]/text()’) |
处理中文乱码:
img_name = img_name.encode(‘iso-8859-1’).decode(‘gbk’)
验证码处理
图鉴
http://www.ttshitu.com/
打开登录页面,找到验证码的网址,然后发送get请求下载验证码。【这里需要使用requests.session,否则再次发送get请求下载验证码的时候,验证码就刷新了,不再是之前的验证码了!代码参见下一节模拟登陆】
先把验证码下载到本地,然后调用以下接口即可。
接口定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import base64
import json
def base64_api(uname, pwd, img):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
code = base64_api('', '', './img.jpg')
超级鹰
http://www.chaojiying.com/
先把验证码下载到本地,然后调用以下接口即可。
接口定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
# 用户中心>>软件ID 生成一个替换 96001
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001')
# 本地图片文件路径 来替换 a.jpg
im = open('./a.jpg', 'rb').read()
# 1902 验证码类型 参考 http://www.chaojiying.com/price.html
print(chaojiying.PostPic(im, 1902))
模拟登陆
发送post请求即可以登录
cookie
手动处理:通过抓包工具获取cookie值,将该值封装到headers中。(不建议)
自动处理:模拟登录post请求后,由服务器端创建。
session
1
2
3
4
5
6
7
8
# 创建一个session对象
session = requests.Session()
# 使用session对象进行模拟登录post请求的发送,cookie就会被存储在session中
session.post(url=login_url, headers=headers, data=data)
# 之后使用携带了cookie的session对象发送get请求,就保持在登录状态了
session.get(url=url, headers=headers)
session处理验证码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 创建session对象
session = requests.Session()
page = session.get(url=url, headers=headers).text
# xpath解析验证码的路径
tree = etree.HTML(page)
img_path = 'https://so.gushiwen.cn/' + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 保存验证码 这里使用session.get 而不是requests.get 否则验证码会刷新!
img = session.get(url=img_path, headers=headers).content
with open('./img.jpg', 'wb') as fp:
fp.write(img)
# 使用打码平台识别验证码
code = base64_api('', '', './img.jpg')
# 使用验证码进行模拟登陆
data = {'code': code, 'username': '', 'password': ''}
response = session.post(url=post_url, data=data, headers=headers)
IP代理
突破自身IP访问的限制,隐藏自身真实IP。
代理相关的网站:
- 快代理
- 西祠代理
- www.goubanjia.com
代理ip的匿名度:
- 透明:服务器知道该次请求使用了代理,也知道请求对应的真实ip
- 匿名:知道使用了代理,不知道真实ip
- 高匿:不知道使用了代理,更不知道真实的ip
方法:
在发送请求的时候,指定proxies参数即可,是字典类型。http或https。
1
requests.get(url=url, headers=headers, proxies={"http": 'http://183.166.139.251:9999'})
异步爬虫
线程池/进程池
1
2
3
4
5
6
7
from multiprocessing.dummy import Pool # 线程池
# from multiprocessing import Pool # 进程池
pool = Pool(4) # 4个线程
pool.map(func, list) # 对list中的每个元素执行func
pool.close()
pool.join()
单线程+异步协程
selenium
浏览器自动化的一个模块
安装
pip install selenium
浏览器驱动安装
Chrome
Windows
配置Chrome环境变量:在用户变量处增加Path: C:\Program Files (x86)\Google\Chrome\Application 【就是安装路径】
下载驱动程序:http://chromedriver.storage.googleapis.com/index.html
将下载好的驱动程序chromedriver.exe放置到目录C:\Program Files (x86)\Google\Chrome\Application下
Linux(ubuntu)
安装Chrome
1
2
3
4
5
6
7
8
9
10
# 安装
sudo apt-get install libxss1 libappindicator1 libindicator7
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome*.deb # Might show "errors", fixed by next line
sudo apt-get install -f
# 查看版本号
google-chrome --version
# 运行
google-chrome --headless --remote-debugging-port=9222 https://chromium.org --disable-gpu --no-sandbox
安装驱动chromedriver
1
2
3
4
5
6
7
8
# 下载
wget -N http://chromedriver.storage.googleapis.com/2.45/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
# 安装 软链接
sudo ln -s /root/chromedriver /usr/local/bin/chromedriver
sudo ln -s /root/chromedriver /usr/bin/chromedriver
# /root/chromedriver 是chromedriver文件的位置
Chrome在Linux下必须使用无头模式,需要设置以下内容
1
2
3
4
5
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
Firefox
Windows
配置Firefox环境变量:在用户变量处增加Path: D:\Mozilla Firefox 【就是安装路径】
下载驱动程序:https://github.com/mozilla/geckodriver/releases/
驱动跟浏览器版本对应:https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
将下载好的驱动程序geckodriver.exe放置到目录 D:\Mozilla Firefox 下
Linux(ubuntu)
安装firefox
1
2
3
4
5
6
7
8
9
1. 在http://www.firefox.com.cn/download/ 下载最新的firefox浏览器linux64位版本
2. 将文件firefox-83.0.tar.bz2复制到Linux,并用 tar -xjvf ... 解压文件得到firefox/目录
3. 将当前目录下的firefox/目录复制到/usr/lib目录下:
mv firefox /usr/lib
4. 进入/usr/bin目录,删除其下的旧版firefox脚本:
cd /usr/bin rm firefox
5. 创建一个软链接,指向/usr/lib/firefox/firefox:
ln -s /usr/lib/firefox/firefox /usr/bin/firefox
6. 查看版本:firefox -version
安装驱动geckodriver
1.下载驱动程序:https://github.com/mozilla/geckodriver/releases/
2.驱动跟浏览器版本对应:https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
3.设置软连接
1
2
3
sudo ln -s /root/geckodriver /usr/local/bin/geckodriver
sudo ln -s /root/geckodriver /usr/bin/geckodriver
# /root/geckodriver 是geckodriver文件的位置
Firefox在Linux下必须使用无头模式,需要设置
1
2
3
4
firefox_options = FirefoxOptions()
firefox_options.add_argument('--headless')
firefox_options.add_argument('--disable-gpu')
browser = webdriver.Firefox(firefox_options=firefox_options)
基本使用
1
2
3
4
5
6
7
8
9
from selenium import webdriver
browser = webdriver.Chrome()
# 不设置环境变量的话,需要直接给出驱动的路径
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
browser.get('url')
page_text = browser.page_source
参考:https://www.cnblogs.com/Maggie2019/p/11016250.html
浏览器相关操作
| 用法 | 代码 |
|---|---|
| 创建浏览器对象 | browser = webdriver.Chrome() |
| 浏览器窗口全屏 | browser.maximize_window() |
| 获取浏览器尺寸 | browser.get_window_size() |
| 设置浏览器尺寸 | browser.set_window_size(w,h) |
| 获取浏览器位置 | browser.get_window_position() |
| 设置浏览器位置 | browser.set_window_position(x,y) |
| 关闭当前标签/窗口 | browser.close() |
| 关闭所有标签/窗口 | browser.quit() |
页面相关操作
| 用法 | 代码 |
|---|---|
| 发起请求打开页面 | browser.get(url) |
| 后退到前一个页面 | browser.back() |
| 前进到后一个页面 | browser.forward() |
| 刷新页面 | browser.refresh() |
| 关闭浏览器 | browser.quit() |
| 获取页面内容 | browser.page_source |
| 获取页面url | browser.current_url |
| 获取页面标题 | browser.title |
| 浏览器全屏显示 | browser.maximize_window() |
| 将当前页面进行截图且保存 | browser.save_screenshot(pic_name) |
元素定位
定位一个元素
- 可能抛出
NoSuchElementException异常 - 返回值类型是<class ‘selenium.webdriver.remote.webelement.WebElement’>,可以进行元素的系列操作
- 只能定位元素,使用xpath时,不能使用/text(),/@attrName,而应该先定位元素,再用元素的操作方法
| 用法 | 代码 |
|---|---|
| id定位 | browser.find_element_by_id(value) |
| name属性值定位 | browser.find_element_by_name(value) |
| 类名定位 | browser.find_element_by_class_name(value) |
| 标签名定位 | browser.find_element_by_tag_name(value) |
| 链接文本定位 | browser.find_element_by_link_text(value) |
| 部分链接文本 | browser.find_element_by_partial_link_text(value) |
| xpath路径表达式 | browser.find_element_by_xpath(value) //返回的不是list |
| css选择器 | browser.find_element_by_css_selector(value) |
定位一组元素
- 返回值类型是<class ‘list’>列表类型
- 列表中存储的类型是<class ‘selenium.webdriver.remote.webelement.WebElement’>
- 对列表中定位到的元素,可以继续定位元素,例如使用xpath的局部解析方式‘./’
| 用法 | 代码 |
|---|---|
| id定位 | browser.find_elements_by_id(value) |
| name属性值定位 | browser.find_elements_by_name(value) |
| 类名定位 | browser.find_elements_by_class_name(value) |
| 标签名定位 | browser.find_elements_by_tag_name(value) |
| 链接文本定位 | browser.find_elements_by_link_text(value) |
| 部分链接文本 | browser.find_elements_by_partial_link_text(value) |
| xpath路径表达式 | browser.find_elements_by_xpath(value) |
| css选择器 | browser.find_elements_by_css_selector(value) |
元素相关操作
| 用法 | 代码 |
|---|---|
| 输入框输入文字 | element.send_keys(data) |
| 清空输入框 | element.clear() |
| 点击元素操作 | element.click() |
| 获取标签位置 | element.location 返回字典类型{’x‘: 10, ‘y’:10} |
| 获取标签大小 | element.size 返回字典类型{’width‘: 10, ‘height’:10} |
| 获取属性值 | element.get_attribute(’name‘) |
| 获取文本内容 | element.text |
| 获取标签名称 | element.tag_name |
| 获取节点id | element.id |
| 继续定位元素 | find_element_by_xpath等函数 |
示例代码:
1
2
3
4
5
6
7
8
browser.get('https://www.taobao.com/')
# 标签定位
search_input = browser.find_element_by_id('q')
# 标签交互
search_input.send_keys('Iphone')
# 点击搜索按钮
button = browser.find_element_by_css_selector('.btn-search')
button.click()
cookies操作
| 用法 | 代码 |
|---|---|
| 获取所有cookies | browser.get_cookies() |
| 获取key对应的值 | browser.get_cookie(key) |
| 设置cookies | browser.add_cookie(cookie_dict) |
| 删除指定名称的cookie | browser.delete_cookie(name) |
| 删除所有cookie | browser.delete_all_cookies() |
执行JavaScript
使用browser.excute_script('jsCode')可以执行js程序
多窗口/多选项卡
| 用法 | 代码 |
|---|---|
| 打开新的选项卡/窗口 | browser.execute_script(‘window.open()’) |
| 获取所有窗口的句柄 | handles = browser.window_handles |
| 通过窗口的句柄进入的窗口 | browser.switch_to.window(handles[n]) |
处理iframe
<iframe>用于在网页内显示网页;<iframe>…</iframe>
如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id),之后才可以调用各种find方法。
switch_to.frame(id) 切换到某个Frame里,所需要的参数是<iframe>标签的id属性的值!
在Iframe中处理完成后,一定要记得switch_to.default_content()回到最外层,否则部分浏览器可能报错。
| 用法 | 代码 |
|---|---|
| 使用id值切换进某个Frame | browser.switch_to.frame(id) |
| 重新切换回上层Frame | browser.switch_to.parent_frame() |
| 跳回最外层的页面 | browser.switch_to.default_content() |
1
2
3
4
5
6
7
8
9
browser = webdriver.Chrome()
browser.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframe_id')
div = browser.find_element_by_id('div_id')
browser.switch_to.default_content()
动作链
用于控制页面完成一些动作,使用ActionChains类
常用方法
下文所说的element或on_element就是使用前文的各种find方法定位到的标签
on_element=None说明若传入element则对这个标签进行操作,否则对当前鼠标位置进行操作
| 方法 | 说明 |
|---|---|
| click(on_element=None) | 鼠标左键点击 |
| click_and_hold(on_element=None) | 鼠标左键点击、不松开 |
| context_click(on_element=None) | 鼠标右键点击 |
| double_click(on_element=None) | 鼠标左键双击 |
| drag_and_drop(source, target) | 拖拽到某个元素然后松开 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽到某个坐标然后松开 |
| key_down(value, element=None) | 按下某个键盘上的键 |
| key_up(value, element=None) | 松开某个键 |
| move_by_offset(xoffset, yoffset) | 鼠标从当前位置移动到某个坐标 |
| move_to_element(to_element) | 鼠标移动到某个元素 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 鼠标移动到距某个元素(左上角坐标)多少距离的位置 |
| perform() | 执行链中的所有动作 |
| release(on_element=None) | 在某个元素位置松开鼠标左键 |
| send_keys(*keys_to_send) | 发送某个键到当前焦点的元素 |
| send_keys_to_element(element, *keys_to_send) | 发送某个键到指定元素 |
参考:https://www.cnblogs.com/colin2012/p/8872291.html
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from selenium.webdriver import ActionChains
# 点击操作
action = ActionChains(driver)
click_btn = driver.find_element_by_xpath('')
action.click(click_btn).perform()
# 移动操作
action = ActionChains(driver)
write = driver.find_element_by_xpath('')
action.move_to_element(write).perform() # 移动到write元素
action.move_by_offset(10, 50).perform() # 移动到距离当前位置(10,50)的点
action.move_to_element_with_offset(write, 10, -40).perform() # 移动到距离write元素(10,-40)的点
# 拖拽操作
dragger = driver.find_element_by_id('dragger') # 被拖拽元素
item1 = driver.find_element_by_xpath('') # 目标1
item2 = driver.find_element_by_xpath('') # 目标2
item3 = driver.find_element_by_xpath('') # 目标3
item4 = driver.find_element_by_xpath('') # 目标4
action = ActionChains(driver)
action.drag_and_drop(dragger, item1).perform() # 1.移动dragger到目标1
action.click_and_hold(dragger).release(item2).perform() # 2.移动dragger到目标2
action.click_and_hold(dragger).move_to_element(item3).release().perform() # 3.移动dragger到目标3
action.drag_and_drop_by_offset(dragger, 400, 150).perform() # 4.移动到指定坐标
action.click_and_hold(dragger).move_by_offset(400, 150).release().perform() # 5.移动到指定坐标
模拟登陆
- 打开登录页面(get)
- 定位到账号和密码的输入框(find_element_by_id)
- 发送数据(send_keys)
- 定位到登录按钮(find_element_by_id)
- 点击登录(click)
验证码处理
- 控制页面进入全屏(maximize_window())
- 打开登录页面(get)
- 页面截屏(save_screenshot(‘./page.png’))
- 定位验证码标签,确定其位置(find/location/size)
- 从整个页面截屏中取出验证码部分图片并保存(PIL库/crop/save)
- 调用云打码接口识别验证码
- 输入验证码(send_keys)/ 使用动作链点击验证码(ActionChains)
- 输入账号密码、点击登录按钮
PIL库
安装:
pip install pillow
使用:
1
2
3
4
5
from PIL import Image
rangle = (5,5,10,10)
i = Image.open('./page.png') # 打开图片
frame = i.crop(rangle) # 截取一个矩形区域
frame.save('./code.png') # 保存图片
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
from selenium.webdriver import ActionChains
from PIL import Image
import time
from selenium import webdriver
from Chaojiying import Chaojiying_Client # 超级鹰打码平台接口
browser = webdriver.Chrome()
# 浏览器全屏
browser.maximize_window()
browser.get('https://kyfw.12306.cn/otn/login/init')
# 页面截屏
browser.save_screenshot('./page.png')
# 找到验证码标签
img = browser.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img')
location = img.location
size = img.size
# 从页面截屏中截取验证码区域
rangle = (int(location['x']), int(location['y']),
int(location['x'] + size['width']), int(location['y'] + size['height']))
i = Image.open('./page.png')
frame = i.crop(rangle)
frame.save('./code.png')
# 验证码识别
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '软件ID')
im = open('./code.png', 'rb').read()
result = chaojiying.PostPic(im, 9004)['pic_str']
all_list = [] # 存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]
if '|' in result:
list_1 = result.split('|')
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = int(list_1[i].split(',')[0])
y = int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
# 输入账号密码
browser.find_element_by_xpath('//*[@id="username"]').send_keys('')
time.sleep(2)
browser.find_element_by_xpath('//*[@id="password"]').send_keys('')
time.sleep(2)
# 使用动作链对每一个列表元素对应的x,y指定的位置进行点击操作
for l in all_list:
# 相对于验证码标签<img>进行偏移,确定位置后点击
ActionChains(browser).move_to_element_with_offset(img, l[0], l[1]).click().perform()
time.sleep(0.5)
# 点击登录按钮
browser.find_element_by_xpath('//*[@id="loginSub"]').click()
time.sleep(10)
browser.quit()
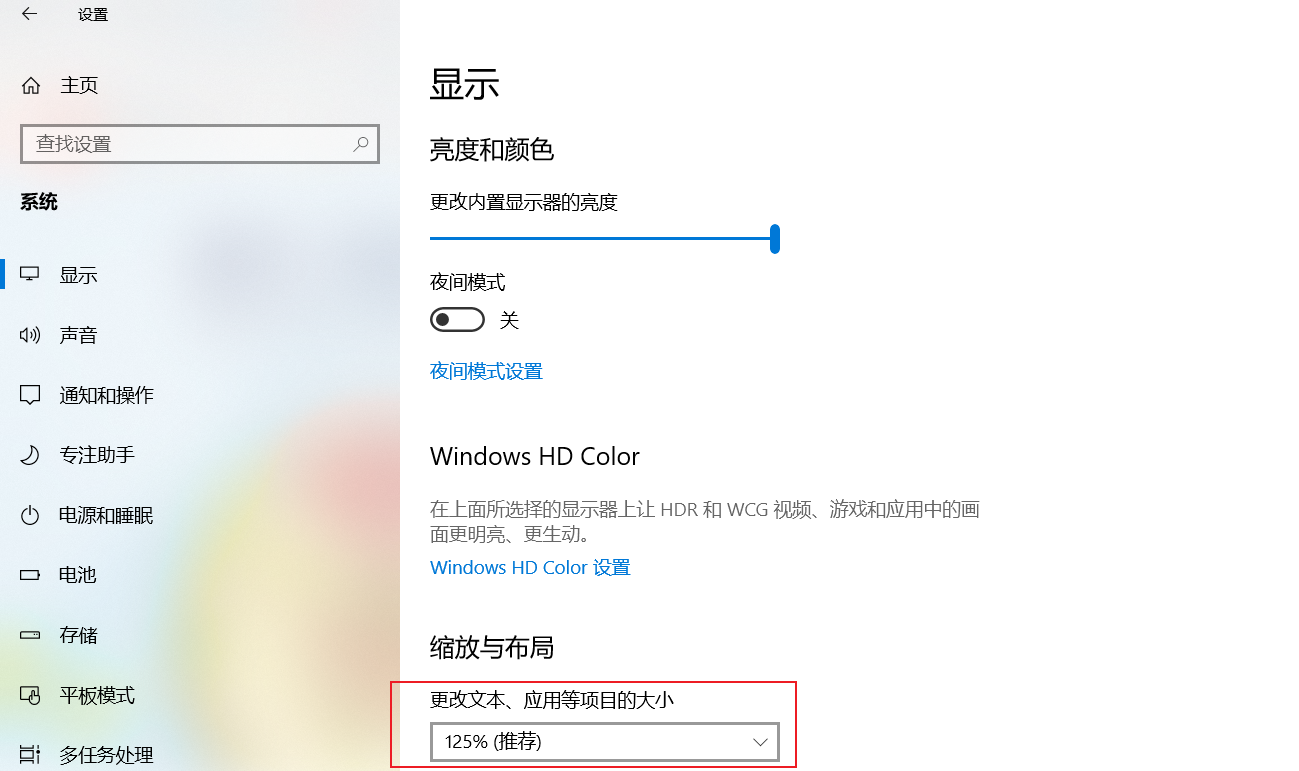
从页面截屏中获取验证码位置存在偏差的修正:
将系统缩放与布局设置为100%即可
无头模式和规避检测
无头模式:不需要显式的打开浏览器页面,直接获取数据
规避检测:避免selenium被网站检测到
部分网站Chrome的无头模式不可用,返回403 Forbidden,可以尝试使用FireFox
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium import webdriver
# 实现无可视化界面
from selenium.webdriver.chrome.options import Options
# 实现规避检测
from selenium.webdriver import ChromeOptions
# 实现无可视化界面
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(chrome_options=chrome_options, options=option)
from selenium.webdriver import FirefoxOptions
# 实现无可视化界面
firefox_options = FirefoxOptions()
firefox_options.add_argument('--headless')
firefox_options.add_argument('--disable-gpu')
browser = webdriver.Firefox(firefox_options=firefox_options)
scrapy
爬虫框架,实现爬虫功能的一个软件结构和功能组件集合
网站级爬虫框架,并发性好,性能较高,一般定制灵活,深度定制困难
安装
pip install scrapy
框架结构
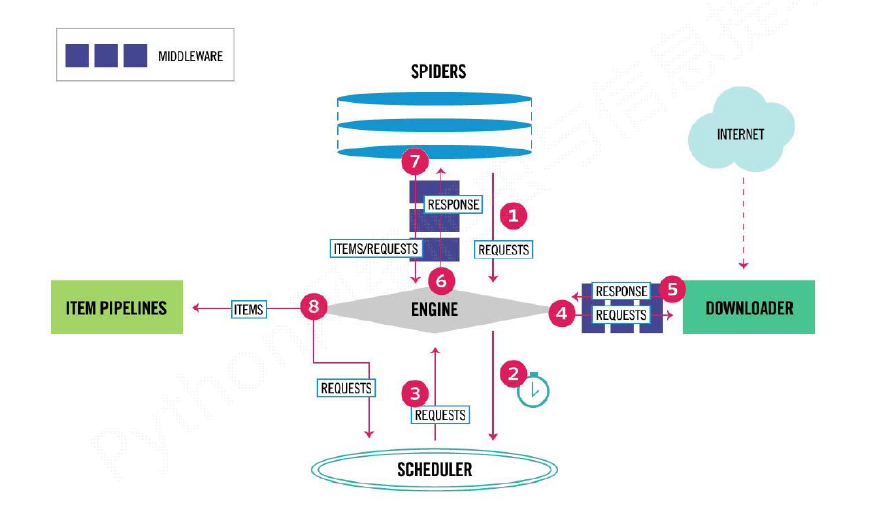
框架流程:
- Engine从Spider处获得爬取请求(Request)
- Engine将爬取请求转发给Scheduler,用于调度
- Engine从Scheduler处获得下一个要爬取的请求
- Engine将爬取请求通过中间件发送给Downloader
- 爬取网页后,Downloader形成响应(Response)
- 通过中间件(下载中间件)发给Engine,Engine将收到的响应(Response)通过中间件发送给Spider处理
- Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
- Engine将爬取项发送给Item Pipeline(框架出口)
- Engine将爬取请求发送给Scheduler
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
五大核心组件:
- 引擎(Engine):用来处理整个系统的数据流处理, 触发事务(框架核心)。
- 调度器(Scheduler):用于接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回。可以想成一个URL的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
- 下载器(Downloader):用于下载网页内容, 并将网页内容返回给Engine。
- 爬虫(Spiders):用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
常用命令
scrapy <command> [options] [args] 命令+选项+参数
| 格式 | 解释 | |
|---|---|---|
| scrapy -h | 查看帮助 | |
| startproject | scrapy startproject <name> [dir] | 创建一个新工程 |
| genspider | scrapy genspider [options] <name> <domain> | 创建一个爬虫 |
| settings | scrapy settings [options] | 获得爬虫配置信息 |
| crawl | scrapy crawl <spider> | 运行爬虫 |
| list | scrapy list | 列出工程中所有爬虫 |
| shell | scrapy shell [url] | 启动URL调试命令行 |
工程目录结构
projectName/ 外层目录
scrapy.cfg 部署Scrapy爬虫的配置文件
projectName/ Scrapy框架的用户自定义Python代码
__init__.py 初始化脚本
items.py Items代码模板(继承类)
middlewares.py Middlewares代码模板(继承类)
pipelines.py Pipelines代码模板(继承类)
settings.py Scrapy爬虫的配置文件
spiders/ Spiders代码模板目录(继承类)
__init__.py 初始文件,无需修改
spiderName.py 爬虫文件
基本流程
创建一个工程:scrapy startproject xxxPro
进入项目目录:cd xxxPro
创建爬虫:scrapy genspider spiderName www.xxx.com
配置爬虫:修改spiderName.py文件,配置start_urls、parse()函数等
运行爬虫:scrapy crawl spiderName
settings.py配置
UA伪装
1
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
是否遵守robots协议
1
ROBOTSTXT_OBEY = False
不输出各种调试信息
1
LOG_LEVEL = 'ERROR'
Spider类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import scrapy
class DemoSpider(scrapy.Spider):
# 爬虫名
name = "demo"
# 允许访问的域名,用于限定start_urls中哪些可用,基本不用这个属性
# allowed_domains = ["python123.io"]
# 起始url列表
# start_urls = ['https://python123.io/ws/demo.html']
# 此函数等价于start_urls = ['https://python123.io/ws/demo.html']
def start_requests(self):
urls = [
'https://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
# 解析函数 对于start_urls中的爬取结果进行解析
def parse(self, response):
# 数据解析处理Response对象,并封装成Item()对象
yield item
Request类
class scrapy.http.Request()
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,’GET’ ‘POST’等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
Response类
class scrapy.http.Response()
Response对象表示一个HTTP响应,由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .text | 返回字符串类型的内容 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
数据解析
Scrapy爬虫支持多种HTML信息提取方法:(解析Response)
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector
使用Xpath Selector
- 使用
response.xpath(''),返回Selector列表,即<class ‘scrapy.selector.unified.SelectorList’>,列表中的元素是<class ‘scrapy.selector.unified.Selector’> - Selector类型可以继续调用xpath进行解析,即
<tag>.xpath(''),注意使用局部解析‘./’。 - /text()、/@attrName返回的列表也不是字符串类型,需要调用
.extract()或者.extract_first()将数据取出来。
.extract():
- 作用到xpath返回的列表SelectorList上,函数返回的是字符串列表。
- 作用到某一个列表元素Selector上,函数返回的是字符串。
- 除了/text()、/@attrName,定位标签时,也可以调用函数把
… 的内容取出来。
.extract_first():
- 只能作用到xpath返回的列表SelectorList上,取出列表里的第一个,函数返回的是字符串。
- 除了/text()、/@attrName,定位标签时,也可以调用函数把
… 的内容取出来。
示例
1
2
3
4
5
6
7
8
div_list = response.xpath('//div')
for div in div_list:
div.xpath('./***').extract_first()
div.xpath('./***').extract()
div.xpath('./***')[0].extract()
response.xpath('/***').extract()
response.xpath('//**')[0].extract()
Item类
class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容,由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
编写items.py文件,定义Item(),可以定义多个Item()
1
2
3
4
5
6
7
8
9
10
11
12
import scrapy
class MyfirstpjtItem(scrapy.Item):
# 定义Item对象的内容
urlname = scrapy.Field()
urlkey = scrapy.Field()
# Item()使用方法
item = MyfirstpjtItem()
item['urlname'] = ''
item['urlkey'] = ''
Pipeline类
首先需要手动开启管道:
在settings.py文件中
1
2
3
4
ITEM_PIPELINES = {
'myfirstpjt.pipelines.MyfirstpjtPipeline': 300,
}
# 300为优先级,数值越小优先级越大
编写pipelines.py,用于处理Item对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import json
import codecs
class MyfirstpjtPipeline(object):
# 开始时调用一次
def open_spider(self,spider):
self.file = codecs.open('mydata.json', 'wb', encoding='utf-8')
# 专门用来处理item类型对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(line)
return item # !!!一定要return item
# 结束时调用一次
def close_spider(self, spider):
self.file.close()
可以在pipelines.py中定义多个Pipeline类,注意需要在settings.py中ITEM_PIPELINES字典中加入这个Pipeline,通过键值来调整优先级,数值越小优先级越大,会按照优先级顺序依次执行多个Pipeline。
爬虫Spider文件提交的item对象只会提交给管道文件中第一个被执行的管道类。
所以在process_item()函数结尾需要return item,否则下一个Pipeline拿不到Item对象了。
使用流程:
- 定义Item类
- 进行数据解析解析Response对象,把解析到的数据封装到Item对象中
- 将Item类型的对象提交给管道(在spiderName.py的
parse()函数中yield item) - 定义Item Pipeline类,对传入的Item对象进行持久化存储(重点编写
process_item()函数)
手动发起请求
对于start_urls中定义的url,会自动发起请求并将结果回传给parse()函数。
若想要手动发起请求,例如对parse()函数从初始页面中解析出的新链接进行请求,可以使用yield scrapy.Request(url=url, callback=self.parse)实现。
1
2
3
4
5
6
7
def parse(self, response):
if self.page_num <= 11:
new_url = format(self.url%self.page_num)
self.page_num += 1
# 手动请求发送
# callback回调函数是专门用作于数据解析,可以指定为另外编写的函数,也可以用parse()
yield scrapy.Request(url=new_url,callback=self.parse)
请求传参
手动发起请求时,如果爬取解析的数据不在同一张页面中时,需要使用不同的数据解析函数。
如果需要向数据解析函数(由callback指定)传递参数,可以指定meta参数,使用 yield scrapy.Request(url=url, callback=self.parse_detail, meta={'item':item})实现。
Spider类中不同的数据解析函数都可以yield item。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class BossSpider(scrapy.Spider):
name = 'boss'
start_urls = ['https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=']
url = 'https://www.zhipin.com/c101010100/?query=python&page=%d'
page_num = 2
# 回调函数接受item
def parse_detail(self, response):
item = response.meta['item']
job_desc = response.xpath('').extract()
item['job_desc'] = job_desc
# 在这个解析函数中yield item
yield item
# 解析首页中的岗位名称
def parse(self, response):
li_list = response.xpath('//*[@id="main"]/div/div[3]/ul/li')
for li in li_list:
item = BossproItem()
job_name = li.xpath('').extract_first()
item['job_name'] = job_name
detail_url = '...'
# 对详情页手动发起请求 获取详情页的页面源码数据
# 请求传参:meta={},可以将meta字典传递给请求对应的回调函数
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item':item})
# 分页操作
if self.page_num <= 3:
new_url = format(self.url%self.page_num)
self.page_num += 1
# 不同页码的页面都使用parse()函数
yield scrapy.Request(url=new_url, callback=self.parse)
图片数据爬取
使用管道类ImagesPipeline
流程:
-
数据解析,解析图片的地址
-
将存储图片地址的Item提交到制定的管道类
-
定义继承
ImagesPipeLine的管道类,实现三个函数:(1)get_media_request
(2)file_path
(3)item_completed
-
在配置文件settings.py中:
(1)开启管道(将自定义管道类加入到
ITEM_PIPELINES字典中)(2)指定图片存储的目录:
IMAGES_STORE = './imgs'
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# pipelines.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class PicpjtPipeline(ImagesPipeline):
# 根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
# 指定图片存储的路径,返回文件名即可。路径在setting.py中指定
def file_path(self, request, response=None, info=None):
imgName = request.url.split('/')[-1]
return imgName
# 返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
# settings.py
ITEM_PIPELINES = {
'picpjt.pipelines.PicpjtPipeline': 300,
}
IMAGES_STORE = './imgs'
# items.py
class PicpjtItem(scrapy.Item):
src = scrapy.Field()
# spiderName.py
# 解析图片src,返回Item()
下载中间件
位置:引擎和下载器之间(MiddlepjtDownloaderMiddleware类)
作用:批量拦截整个工程中的所有的请求和响应
使用方法:
-
首先需要手动开启中间件:
在settings.py文件中
1 2 3
DOWNLOADER_MIDDLEWARES = { 'middlepjt.middlewares.MiddlepjtDownloaderMiddleware': 543, }
-
编写middlewares.py文件中的
MiddlepjtDownloaderMiddleware类。
拦截请求:
拦截所有请求,进行UA伪装、IP代理等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# middlewares.py的MiddlepjtDownloaderMiddleware类中
# 拦截所有请求,进行UA伪装
def process_request(self, request, spider):
# UA伪装 user_agent_list中随机挑选一个
request.headers['User-Agent'] = random.choice(self.user_agent_list)
return None
# 拦截发生异常的请求,进行IP代理
# 必须将修改后的Request返回:return request
# 根据url选择http或https,从IP池中随机选择代理
def process_exception(self, request, exception, spider):
if request.url.split(':')[0] == 'http':
# IP代理
request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http)
else:
request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
# 将修正之后的请求对象进行重新发送!!
return request
拦截响应:
拦截所有请求返回的Response,应用场景是假如网页内容需要动态加载,可以在这里进行拦截并处理,将加载好的数据返回给Spider进行数据解析。
结合selenium可以便捷的获取动态加载数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# middlewares.py的MiddlepjtDownloaderMiddleware类中
from scrapy.http import HtmlResponse
from time import sleep
def process_response(self, request, response, spider):
# 获取了在爬虫类中定义的浏览器对象
browser = spider.browser
# 根据url挑选出指定的响应对象进行篡改(只篡改想要篡改的响应)
if request.url in spider.models_urls:
browser.get(request.url) # 打开页面
sleep(3)
page_text = browser.page_source # 动态加载的数据
# 对响应进行篡改,修改其内容body=page_text
new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return new_response
else:
# 其他请求对应的响应对象直接返回
return response
# SpiderName.py中
# 需要实例化selenium.webdriver 浏览器对象
from selenium import webdriver
# 爬虫初始化
def __init__(self):
# 实例化一个浏览器对象
self.browser = webdriver.Chrome()
# 爬虫关闭时
def closed(self, spider):
# 关闭浏览器对象
self.browser.quit()
# 解析函数如parse()就跟一般的没有区别,因为动态加载的内容直接从中间件返回回来了
CrawlSpider类
Spider的一个子类,可以自动识别符合要求的链接进行爬取,常用于全站数据爬取。
创建爬虫文件命令:
scrapy genspider -t crawl spiderName www.xxx.com
链接提取器:
LinkExtractor类,根据指定的规则(正则表达式,参数为allow)进行指定链接的提取。
规则解析器:
Rule类,将链接提取器提取到的链接进行指定规则的解析(参数为callback,不解析数据的话可以不指定callback),参数follow=True的含义为可以将链接提取器继续作用到链接提取器所提取到的链接对应的页面中。
工作过程:
首先爬取start_urls,根据Rule对爬取的内容进行解析,找到匹配的url,调用数据解析方法(parse_item)对相应的url的页面进行解析。并不是对start_urls调用parse_item。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from mycrawlpjt.items import MycrawlpjtItem
class MycrawlSpider(CrawlSpider):
name = 'mycrawl'
allowed_domains = ['sohu.com']
start_urls = ['http://news.sohu.com/']
rules = (
# http://www.sohu.com/a/328591875_267106
# 提取链接的规则
Rule( # 规则解析器
LinkExtractor( # 链接提取器
allow='http://www\\.sohu\\.com/a/.*', # 正则
allow_domains='sohu.com',
),
callback='parse_item', # 每调用一次就解析一次链接提取器提取到链接对应的页面内容
follow=True), # 对链接提取器提取到的链接的页面继续提取链接
)
def parse_item(self, response): # 解析已经提取出来的链接
item = MycrawlpjtItem()
item['name'] = response.xpath("/html/head/title/text()").extract()
item['link'] = response.xpath("//link[@rel='canonical']/@href").extract()
return item
常见应用场景:
爬取带页码的不同页面,不再需要遍历pageNum,可以使用Rule来识别,由于一个页面中可能并不能包含全部页码的页面链接,设置follow=True即可获取全部页码,即全站数据了。
1
2
3
4
5
6
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
rules = (
Rule(LinkExtractor(allow='/political/index/politicsNewest\?id=1&page=\\d+'), callback='parse_item', follow=True),
)
# 因为这个页面中的其他页面的链接就是不完整的,不是http开头,所以allow的正则才是这样的!!
定义多个Rule以提取不同的链接:
如果爬取解析的数据不在同一张页面中时,就可以使用不同的Rule并使用不同的数据解析函数。此时不需要手动发起请求,也就不能手动请求传参,也就是不同的解析函不能使用同一个Item()对象了。(需要定义多个Item()类,除非不同页面解析的数据是相同类型)
多个Rule的工作过程:
首先爬取start_urls,根据Rule1对爬取的内容进行解析,找到匹配的url,调用数据解析方法(parse_item)对相应的url的页面进行解析。对Rule1解析到的url,使用Rule2对爬取的内容进行解析,找到匹配的url,调用数据解析方法(parse_detail)对相应的url的页面进行解析。
即,后边的Rule对前边的Rule爬取到的url使用正则进行匹配,而不是对start_urls进行匹配。这样爬取的数据就更多了。
例如:可以使用第一个Rule实现翻页以爬取全站数据,使用第二个Rule对全站数据的详情页面进一步解析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class SunSpider(CrawlSpider):
name = 'sun'
start_urls = ['']
# 链接提取器:根据指定规则(allow="正则")进行指定链接的提取
link = LinkExtractor(allow=r'')
link_detail = LinkExtractor(allow=r'')
rules = (
# 规则解析器:使用多个Rule
Rule(link, callback='parse_item', follow=True),
Rule(link_detail,callback='parse_detail')
)
# 结合不同的数据解析函数
def parse_item(self, response):
item = SunproItem()
...
yield item
def parse_detail(self,response):
item = DetailItem()
...
yield item
分布式爬虫
安装环境:
pip install scrapy-redis
作用:
可以给原生的scrapy框架提供可以被共享的管道和调度器
实现流程:
(1)创建一个工程: scrapy startproject xxxPro
(2)创建一个基于CrawlSpider的爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com
(3)修改当前的爬虫文件spiderName.py:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 将start_urls和allowed_domains进行注释
- 添加一个新属性:redis_key = ‘sun’ 即被共享的调度器队列的名称(不一定是’sun’)
- 编写数据解析相关的操作,yield item
(4)修改配置文件settings.py:
- 指定使用可以被共享的管道:
1
2
3
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 指定调度器:
1
2
3
4
5
6
7
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。
# 如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器:
1
2
REDIS_HOST = '127.0.0.1' #redis远程服务器的ip(修改)
REDIS_PORT = 6379
(5)redis相关操作配置:
- 配置redis的配置文件:
- windows下为redis.windows.conf
- linux或者mac下为redis.conf
- 修改配置文件:
- 将bind 127.0.0.1进行删除
- 关闭保护模式:protected-mode yes改为no
-
开启redis服务: ./redis-server redis.windows.conf
- 启动客户端: ./redis-cli
(6)执行工程
- cd proName/spiders/
- scrapy runspider spiderName.py
(7)向调度器的队列中放入一个起始的url
-
在redis命令行输入:lpush 队列名 起始url(start_urls)
例如:lpush sun http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1
(8)爬取到的数据存储在redis的proName:items这个数据结构中
- 查看数据:lrange proName:items 0 -1
- 查看数据库的键:keys *
增量式爬虫
重点是对已经爬取过的url不要重复爬取。
解决办法:使用文件/数据库来记录爬取过的url,对爬取过的url不再重复爬取。
例如,使用Redis数据库的set来判断是否爬取过:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
from redis import Redis
class MovieSpider(CrawlSpider):
conn = Redis(host='127.0.0.1', port=6379)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
# 获取详情页的url
detail_url = li.xpath('./div/a/@href').extract_first()
# 将详情页的url存入redis的set中
ex = self.conn.sadd('urls', detail_url)
if ex == 1:
print('该url没有被爬取过,可以进行数据的爬取')
yield scrapy.Request(url=detail_url, callback=self.parse_detail)
else:
print('数据还没有更新,暂无新数据可爬取!')
def parse_detail(self, response):
yield item
class MoviepjtPipeline(object):
# 开始时调用一次
def open_spider(self,spider):
# 追加模式 避免覆盖
self.file = codecs.open('mydata.json', 'ab', encoding='utf-8')
# 专门用来处理item类型对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(line)
return item
# 结束时调用一次
def close_spider(self, spider):
self.file.close()
urllib3
参考
https://www.bilibili.com/video/BV1Yh411o7Sz
https://www.icourse163.org/course/BIT-1001870001
https://deerchao.cn/tutorials/regex/regex.htm
https://www.cnblogs.com/Maggie2019/p/11016250.html
https://www.cnblogs.com/colin2012/p/8872291.html

