C++
C语言基础
C++基础
引用
定义引用
1
2
int n = 4;
int & r = n; // r引用了 n, r的类型是 int &
某个变量的引用,等价于这个变量,相当于该变量的一个别名。
定义引用时一定要将其初始化成引用某个变量。
1
2
3
4
5
6
7
int n = 4;
int & r = n;
r = 4;
cout << r; //输出 4
cout << n; //输出 4
n = 5;
cout << r; //输出5
引用初始化后,它就一直引用该变量,不会再引用别的变量了。
引用只能引用变量,不能引用常量和表达式。
1
2
3
4
5
6
7
8
9
10
double a = 4, b = 5;
double & r1 = a;
double & r2 = r1; // r2也引用 a
r2 = 10;
cout << a << endl; // 输出 10 对引用赋值会修改原变量的值
r1 = b; // r1并没有引用b
cout << a << endl; // 输出 5
int n = 4;
int & r = n * 5; // 错误,不可以引用表达式
引用做函数形参
1
2
3
4
5
6
7
8
void swap(int & a,int & b)
{
int tmp; tmp=a; a=b; b=tmp;
}
int x=1,y=2;
swap(x,y);
cout<<x<<" "<<y<<endl; // 2, 1
引用做函数返回值
1
2
3
4
5
6
7
8
int n = 4;
int & SetValue() { return n; }
SetValue() = 40;
//SetValue()返回n的引用,并赋值40 相当于以下两句
//int & t = SetValue();
//t = 40;
cout<<n<<endl; // 输出40
常引用
定义引用时,前面加const关键字,即为“常引用”
1
2
int n;
const int & r = n; //r的类型是 const int &
不能通过常引用去修改其引用的内容,可以修改原变量来修改引用的值
1
2
3
4
5
int m = 100;
const int & w = m;
//w = 200; // 编译错
m = 300; // 没问题
cout << w << " " << m; // 输出300 300
T & 类型的引用或T类型的变量可以用来初始化const T & 类型的引用。
const T 类型的常变量和const T & 类型的常引用则不能用来初始化T &类型的引用,除非进行强制类型转换。
1
2
3
4
5
6
7
8
9
10
11
12
int n = 8;
const int & r1 = n;
//int & r2 = r1; // 错误 不能用const初始化非const
const int q = 10;
const int & ww = q; // 正确 使用常引用去引用常量
//int & e = q; // 错误 常量不能去初始化非const的引用
int n = 8;
int & r1 = n;
const int r2 = r1; // 正确 r2是常量,不管n、r1怎么变,r2都不变,且不能对r2赋值
const int & r3 = r1; // 正确 r3是常引用,随着n、r1改变,但是不能对r3赋值
函数参数使用常引用,可以避免对实参的值造成修改。
const关键字
(1)定义常量:
普通常量
const int MAX_VAL = 23;
常量对象
- 如果不希望某个对象的值被改变,则定义该对象的时候可以在前面加
const关键字。 - 常量对象只能使用构造函数、析构函数和常量方法。
(2)定义常量指针。
const在指针的左边,表示不可通过常量指针修改其指向的内容,但常量指针的指向可以变化。
1
2
3
4
5
int n, m;
const int * p = & n;
* p = 5; //编译出错
n = 4; //ok
p = &m; //ok, 常量指针的指向可以变化
不能把常量指针赋值给非常量指针,反过来可以。
1
2
3
4
5
const int * p1;
int * p2;
p1 = p2; //ok
p2 = p1; //error
p2 = (int *) p1; //ok, 强制类型转换
函数参数为常量指针时,可避免函数内部不小心改变参数指针所指地方的内容。
1
2
3
4
5
void MyPrintf( const char * p )
{
strcpy( p, "this"); //编译出错
printf("%s", p); //ok
}
若const在指针的右边,表示指针指向的内存地址不能够被改变,但其内容可以改变。
1
2
3
4
5
int a = 8;
int* const p = &a;
*p = 9; // 正确
int b = 7;
p = &b; // 错误
(3)定义常引用。
函数参数使用常引用,可以避免对实参的值造成修改。
(4)常量成员。
(5)修饰函数返回值。
const 修饰内置类型的返回值,修饰与不修饰返回值作用一样。
const 修饰自定义类型的作为返回值,此时返回的值不能作为左值使用,既不能被赋值,也不能被修改。
const 修饰返回的指针或者引用,也是不能做左值。
1
2
3
4
5
6
7
8
9
10
A& test(A& a) {
return a;
}
// 不加const则可以这样:
test(a) = b;
const A& test(A& a) {
return a;
}
// 加了const就不可以了
动态内存分配
用new运算符实现动态内存分配,用delete运算符释放动态分配的内存
(1)P = new T; delete P;
T是任意类型名,P是类型为T * 的指针。
动态分配出一片大小为sizeof(T)字节的内存空间,并且将该内存空间的起始地址赋值给P。
1
2
3
4
int* p;
p = new int;
*p = 5;
delete p;
(2)P = new T[N]; delete [] P;
T :任意类型名
P :类型为T * 的指针
N :要分配的数组元素的个数,可以是整型表达式。
动态分配出一片大小为sizeof(T)*N字节的内存空间,并且将该内存空间的起始地址赋值给P。
1
2
3
4
5
6
int * pn;
int i = 5;
pn = new int[i * 20];
pn[0] = 20;
//pn[100] = 30; //编译没问题。运行时导致数组越界
delete [] pn;
内联函数
为了减少函数调用的开销,引入了内联函数机制。
编译器处理对内联函数的调用语句时,是将整个函数的代码插入到调用语句处,而不会产生调用函数的语句。
使用关键字inline实现内联。
1
2
3
4
5
inline int Min(int a,int b)//内联函数
{
if(a<b) return a;
return b;
}
函数重载
一个或多个函数,名字相同,然而参数个数或参数类型不相同,这叫做函数的重载。
对于指针和引用类型的参数,const关键字可以作为区别条件。
返回值类型不同不构成重载。
编译器根据调用语句的中的实参的个数和类型判断应该调用哪个函数。
1
2
3
4
5
6
7
8
9
10
11
int Max(double f1,double f2) { }
int Max(int n1,int n2) { }
int Max(int n1,int n2,int n3) { }
Max(3.4,2.5); //调用 (1)
Max(2,4); //调用 (2)
Max(1,2,3); //调用 (3)
Max(3,2.4); //error,二义性
int f(int & a){}
int f(const int & a){}
函数缺省参数
定义函数的时候可以让最右边的连续若干个参数有缺省值。
在调用函数的时候,若相应位置不写参数,参数就是缺省值。
不能通过设置缺省参数来构成重载。
1
2
3
4
void func( int x1, int x2 = 2, int x3 = 3) { }
func(10 ) ; //等效于 func(10,2,3)
func(10,8) ; //等效于 func(10,8,3)
func(10, , 8) ; //不行,只能最右边的连续若干个参数缺省
类和对象
定义类和对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class CRectangle
{
public:
int w, h;
void Init( int w_,int h_ ) {
w = w_; h = h_;
}
};
CRectangle r; //r是一个对象
r.Init(5,4);
CRectangle r1;
CRectangle * p1 = & r1;
p1->w = 5;
p1->Init(5,4); //Init作用在p1指向的对象上
CRectangle & rr = r1;
rr.w = 5;
rr.Init(5,4); //rr的值变了,r1也变了
对象所占用的内存空间的大小,等于所有成员变量的大小之和。
每个对象各有自己的存储空间。一个对象的某个成员变量被改变了,不会影响到另一个对象。
成员变量
用下列关键字来说明类成员可被访问的范围:
- private: 私有成员,只能在成员函数内访问。不能用
对象.变量名的方式访问 - public : 公有成员,可以在任何地方访问。
- protected: 保护成员。不能用
对象.变量名的方式访问
以上三种关键字出现的次数和先后次序都没有限制,若缺省默认为是私有成员。
在类的成员函数内部,能够访问:
- 当前对象的全部属性、函数;
- 同类其它对象的全部属性、函数。
在类的成员函数以外的地方,只能够访问该类对象的公有成员。
用struct定义类和用class的唯一区别:缺省默认为是公有成员。
成员函数
- 成员函数可以重载及参数缺省。
- 成员函数可以不在类中定义函数体,只保留函数声明,而在类外进行函数定义,使用符号
类名::函数名。 - 成员函数的缺省参数只可以在函数声明或函数定义中定义一次,一般写在函数声明中。
- **成员函数使用缺省参数时,要注意函数重载,防止出现二义性。 **
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Complex{
private:
double real,imag;
public:
void Set(double r,double i=0); // 只有函数声明,没有函数体
//void Set(double r); // 导致二义性
};
void Complex::Set(double r,double i) // 这里不能再写i=0这个缺省参数了,否则编译错。
{
real = r;
imag = i;
}
Complex c3(); //这个适用于编译器的默认构造,也适用于自己写的无参构造
Complex c4; //这个适用于编译器的默认构造,也适用于自己写的无参构造
构造函数
- 名字与类名相同,可以有参数,不能有返回值。
- 作用是对对象进行初始化,如对成员变量赋初值。
- 如果没有定义构造函数,则编译器生成一个默认的无参数的构造函数,默认构造函数,不做任何操作。
- 如果定义了构造函数,编译器就不生成默认的无参构造函数了。
- 对象生成时构造函数自动被调用。对象一旦生成,就再也不能在其上执行构造函数。
- 一个类可以有多个构造函数(重载)。
- 构造函数最好是
public的,private构造函数不能直接用来初始化对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Complex{
private:
double real,imag;
public:
Complex(); //此时只有函数声明,需要在类外部补充函数定义 完整写法是:Complex(){};
Complex(double r,double i=0);
};
Complex::Complex(double r,double i)
{
this->real = r;
this->imag = i;
}
Complex::Complex() //定义无参构造函数!也需要写函数体,或者直接在声明处写{}
{
}
Complex c1(2);
Complex c2(2,4);
Complex * pc3 = new Complex(2,4);
delete pc3;
Complex c3(); //这个适用于编译器的默认构造,也适用于自己写的无参构造
Complex c4; //这个适用于编译器的默认构造,也适用于自己写的无参构造
构造函数在数组中的应用
1
2
3
4
5
6
7
8
9
10
11
12
13
class Test {
public:
Test(int n) { } //(1)
Test(int n, int m) { } //(2)
Test() { } //(3)
};
Test a1[3] = { 1, Test(1,2) };
// 三个元素分别用(1),(2),(3)初始化
Test a2[3] = { Test(2,3), Test(1,2) , 1};
// 三个元素分别用(2),(2),(1)初始化
Test * pArray[3] = { new Test(4), new Test(1,2) };
//两个元素分别用(1),(2) 初始化
初始化列表
构造函数初始化列表以一个冒号开始,接着是以逗号分隔的数据成员列表,每个数据成员后面跟一个放在括号中的初始化式,用来对成员进行初始化。
1
2
3
4
5
6
7
8
9
10
11
class Complex{
private:
double real,imag;
public:
Complex(double r,double i): real(r), imag(i) {}
// 等价于:
// Complex(double r,double i) {
// real = r;
// imag = i;
// }
};
必须使用初始化列表的情况:
(1)需要初始化的数据成员是对象时:
数据成员是对象,并且这个对象只有含参数的构造函数,没有无参数的构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Test1
{
public:
int i;
Test1(int a):i(a) {}
};
class Test2
{
public:
Test1 test1;
//使用初始化列表完成
Test2(int x): test1(x) {}
// Test2(Test1 & t1) { //error 因为Test1没有无参构造函数
// test1 = t1; //这样的赋值,首先需要默认初始化test1再赋值,导致报错
// }
};
(2)需要初始化const修饰的类成员
1
2
3
4
5
6
7
class Test3
{
private:
const int a; //const成员声明
public:
Test3() :a(10) {} //初始化
};
(3)需要初始化引用成员
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Test4
{
private:
int &a; //声明
public:
Test4(int a_) :a(a_) {} //初始化
};
class Test5
{
public:
Test1& test1;
Test5(Test1& t1):test1(t1){}
};
(4)子类初始化父类时(见后文)
子类使用初始化列表初始化父类,因为调用子类构造函数之前先调用父类的构造函数,所以不能在子类函数内去初始化父类。
1
2
3
4
5
6
7
8
9
10
11
12
13
class Base {
public:
int n;
Base(int i):n(i) {}
~Base() {}
};
class Derived:public Base
{
public:
Derived(int i):Base(i) {} // 使用初始化列表初始化父类
~Derived() {}
};
复制构造函数
- 只有一个参数,即对同类对象的引用。
- 形如
X::X(X &)或X::X(const X &), 二者选一。后者能以常量对象作为参数。 - 不允许有形如
X::X( X )的构造函数。 - 如果没有定义复制构造函数,那么编译器生成默认复制构造函数。默认的复制构造函数完成复制功能。
- 如果定义了自己的复制构造函数,则默认的复制构造函数不存在。
- 可以发生在初始化的时候,不可以发生在变量间赋值的时候。
1
2
3
4
5
6
7
class Complex {
private :
double real,imag;
};
Complex c1; //调用缺省无参构造函数
Complex c2(c1); //调用缺省的复制构造函数,将c2初始化成和c1一样
使用场景:
(1)当用一个对象去初始化同类的另一个对象时。
变量之间的赋值不会调用复制构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Complex{
private:
double real,imag;
public:
Complex(double r,double i=0);
Complex(const Complex &c) { //复制构造函数,传进来的是引用
real = c.real;
imag = c.imag;
cout<<"copy"<<endl;
}
};
Complex c1(2,3); //正常调用构造函数
Complex c2(c1); //调用复制构造函数
Complex c3=c1; //调用复制构造函数,初始化语句,非赋值语句
c3=c1; //变量之间的赋值不会调用复制构造函数
(2)如果某函数有一个参数是类 A 的对象, 那么该函数被调用时,类A的复制构造函数将被调用。
如果函数参数是类A的引用类型,就不会调用复制构造函数了。
使用引用做参数,如果希望实参的值不被改变,可以加上const关键字。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class A
{
public:
int v;
A() { };
A(int n) { v = n; };
A(const A & a) {//复制构造函数
v = a.v;
cout << "A Copy constructor called" <<endl;
}
};
void Func(A a1) { }
void Func2(A & a1) { }
void Func3(const A & a1) { } //函数内部不能对a1赋值,也就保证了实参不会被修改。
A a2;
Func(a2); //调用复制构造函数
Func2(a2); //不会调用复制构造函数
Func3(a2); //不会调用复制构造函数,且函数不会导致a2的值被改变
(3)如果函数的返回值是类A的对象时,则函数返回时,A的复制构造函数被调用。
这里生成的临时对象有可能被编译器优化掉。
1
2
3
4
5
6
A Func4(){
A b(4);
return b;
}
cout<<Func4().v<<endl; //调用复制构造函数
类型转换构造函数
- 定义转换构造函数的目的是实现类型的自动转换。
- 只有一个参数,而且不是复制构造函数的构造函数,一般就可以看作是转换构造函数。
- 当需要的时候,编译系统会自动调用转换构造函数,建立一个无名的临时对象(或临时变量)。
- 可以发生在初始化的时候,也可以发生在赋值的时候(但不是变量间的赋值)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class A
{
public:
int v;
A() { };
A(int n) { v = n; }; //类型转换构造函数
};
A a1(4); //调用类型转换构造函数
A a2 = 4; //调用类型转换构造函数,4被自动转换成一个临时的A的对象(初始化)
A a3; //调用默认构造函数
a3 = 9; //调用类型转换构造函数,9被自动转换成一个临时的A的对象(赋值)
A a4,a5; //调用默认构造函数
a4 = a5; //变量之间的赋值不会调用复制构造函数,也没有调用类型转换构造函数
析构函数
- 函数名在类名前面加‘~’, 没有参数和返回值。
- 析构函数对象消亡时即自动被调用。
- 如果没有定义析构函数,则编译器生成缺省析构函数。缺省析构函数什么也不做。
- 如果定义了析构函数,则编译器不生成缺省析构函数。
- 一个类最多只能有一个析构函数。
- 对象数组生命期结束时,对象数组的每个元素的析构函数都会被调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class String{
private :
char * p;
public:
String () {
p = new char[10];
}
~ String () ; //析构函数
};
String ::~ String()
{
delete [] p;
}
析构函数在数组中的应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Ctest {
public:
~Ctest() { cout<< "destructor called" << endl; }
};
int main () {
Ctest array[2];
cout << "End Main" << endl;
return 0;
}
输出:
End Main
destructor called
destructor called
delete 运算导致析构函数调用
1
2
3
4
5
6
Ctest * pTest;
pTest = new Ctest; // 构造函数调用1次
delete pTest; // 析构函数调用1次
pTest = new Ctest[3]; // 构造函数调用3次
delete [] pTest; // 析构函数调用3次
析构函数在对象作为函数返回值返回后被调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class CMyclass {
public:
CMyclass() { cout << "constructed" << endl; }
CMyclass(const CMyclass & x) { cout << "copy constructed" << endl; }
~CMyclass() { cout << "destructor" << endl; }
};
CMyclass obj; //main结束析构
CMyclass fun(CMyclass sobj) { // 参数对象消亡也会导致析构函数被调用
return sobj; // 函数调用返回时,生成临时对象返回
}
int main()
{
obj = fun(obj); //函数调用的返回值(临时对象)被用过后,会被析构
//这个赋值语句本身是给已经存在的对象obj赋值,不会调用任何构造函数
return 0;
}
// 输出:
constructed //构造obj
copy constructed //fun函数传参,导致调用复制构造函数
copy constructed //fun函数返回对象,导致调用复制构造函数
destructor //析构fun函数的参数这个临时对象
destructor //析构fun函数的返回值这个临时对象
destructor //析构obj
// 如果fun函数参数加引用,即fun(CMyclass & sobj),则不会因为传参调用复制构造函数,也就不会产生临时对象,也就不会析构这个临时对象,导致缺少一个copy constructed和一个destructor。
不同编译器的处理不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class A {
public: int x;
A(int x_):x(x_) {
cout << x << " constructor called" << endl;
}
A(const A & a ) { //本例中dev需要此const其他编译器不要
x = 2 + a.x;
cout << "copy called" << endl;
}
~A() {
cout << x << " destructor called" << endl;
}
};
A f( ){
A b(10);
return b;
}
int main( ){
A a(1);
a = f();
return 0;
}
//Visual Studio输出结果:
1 constructor called // 构造a
10 constructor called // 构造b
10 destructor called // 析构b 因为b是局部变量
copy called // 复制构造 因为f()函数返回值是对象,会产生一个临时对象,值=12
12 destructor called // 析构f()函数的返回值这个临时对象
12 destructor called // 析构a 由于a=f(),此时a=12
//Dev C++输出结果:
1 constructor called // 构造a
10 constructor called // 构造b
10 destructor called // 析构b 因为b是局部变量
10 destructor called // 析构a
//说明dev出于优化目的并未生成返回值这个临时对象
静态成员
静态成员:
- 在定义前面加了
static关键字的成员。 - 静态成员不需要通过对象就能访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
class CRectangle
{
private:
int w, h;
static int nTotalArea;
static int nTotalNumber;
public:
CRectangle(int w_,int h_);
~CRectangle();
static void PrintTotal();
};
int CRectangle::nTotalNumber=0; // 静态成员的显式的初始化,需要写上类型
静态成员变量
- 普通成员变量每个对象有各自的一份,而静态成员变量为所有对象共享,只有一份。
- 静态成员变量需要显式的初始化,需要写清楚变量类型。
sizeof运算符不会计算静态成员变量。
静态成员函数
- 普通成员函数必须具体作用于某个对象,而静态成员函数并不具体作用于某个对象。
- 在静态成员函数中,不能访问非静态成员变量,也不能调用非静态成员函数。
访问静态成员
-
类名::成员名
CRectangle::PrintTotal();CRectangle::nTotalNumber; -
对象名.成员名
CRectangle r; r.PrintTotal(); -
指针->成员名
CRectangle * p = &r; p->PrintTotal(); -
引用.成员名
CRectangle & ref = r; int n = ref.nTotalNumber;
this指针
作用是指向成员函数所作用的对象。
类的非静态成员函数,真实的参数比所写的参数多1。
静态成员函数中不能使用 this 指针,因为静态成员函数并不具体作用与某个对象。
因此,静态成员函数的真实的参数的个数,就是程序中写出的参数个数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Complex {
public:
double real, imag;
void Print() { cout << real << "," << imag ; }
Complex(double r,double i):real(r),imag(i) { }
Complex AddOne() {
this->real ++; //等价于 real ++;
this->Print(); //等价于 Print
return * this;
}
}
class A {
int i;
public:
void Hello() { cout << i << "hello" << endl; }
//void Hello(A * this ) { cout << this->i << "hello" << endl; } 相当于这个
}
封闭类
有成员对象的类叫封闭(enclosing)类
- 封闭类对象生成时,先执行所有对象成员的构造函数,然后执行封闭类的构造函数。
- 对象成员的构造函数调用次序和对象成员在类中的说明次序一致,与在成员初始化列表中出现的次序无关。
- 封闭类对象消亡时,先执行封闭类的析构函数,然后执行成员对象的析构函数。次序和构造函数的调用次序相反。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class CTyre {
public:
CTyre() { cout << "CTyre contructor" << endl; }
~CTyre() { cout << "CTyre destructor" << endl; }
};
class CEngine {
public:
CEngine() { cout << "CEngine contructor" << endl; }
~CEngine() { cout << "CEngine destructor" << endl; }
};
class CCar {
private:
CEngine engine;
CTyre tyre;
public:
CCar() { cout << "CCar contructor" << endl; }
~CCar() { cout << "CCar destructor" << endl; }
};
CCar car;
/* 输出:
CEngine contructor
CTyre contructor
CCar contructor
CCar destructor
CTyre destructor
CEngine destructor
*/
友元
友元函数
一个类的友元函数可以访问该类的私有成员。
友元函数可以是其他类的成员函数(包括构造、析构函数),也可以是全局函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class CCar ; //提前声明 CCar 类,以便后面的CDriver类使用
class CDriver
{
public:
void ModifyCar( CCar * pCar);
};
class CCar
{
private:
int price;
friend int MostExpensiveCar( CCar cars[], int total); // 声明友元函数
friend void CDriver::ModifyCar(CCar * pCar); // 声明友元函数
};
void CDriver::ModifyCar(CCar * pCar)
{
pCar->price+=100; // 直接访问price
}
int MostExpensiveCar( CCar cars[], int total)
{
}
友元类
如果A是B的友元类,那么A的成员函数可以访问B的私有成员。
友元类之间的关系不能传递,不能继承,也不是对称的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class A
{
private:
int price;
friend class B; // 声明B为A的友元类 B的成员函数可以访问A的私有成员
};
class B
{
public:
A a;
void f() {
a.price += 1000; // 因B是A的友元类,故此处可以访问其私有成员
}
};
常量成员函数
常量对象
- 如果不希望某个对象的值被改变,则定义该对象的时候可以在前面加
const关键字。 - 常量对象只能使用构造函数、析构函数和常量方法。
const对象只能访问const成员函数,而非const对象可以访问任意的成员函数,包括const成员函数。
常量成员变量
- 在成员变量前加
const表示成员变量不能被修改,同时只能在初始化列表中赋值。
常量成员函数
- 在类的成员函数说明后面加
const关键字,则该成员函数成为常量成员函数。 - 常量成员函数内部不能改变属性的值,也不能调用非常量成员函数。
- 常量成员函数在声明和定义处都要加
const关键字。 - 相同名字和参数表的两个函数,通过有无
const可以实现重载,根据对象的类型实现调用哪个函数的判断。 const关键字不能与static关键字同时使用。mutable成员变量可以在常量成员函数中修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class Sample {
private :
const int a;
int value;
mutable int mv;
public:
void func() { };
Sample():a(10) { value = 10; } // 使用初始化列表初始化a
void SetValue() const { // 常量成员函数 声明和定义都要const
//value = 0; // wrong
//func(); //wrong
mv = 8;
}
void PrintValue() const;
void PrintValue(); // 重载
};
void Sample::PrintValue() const { // 此处不使用const 会导致编译出错
cout << value + mv << endl;
}
void Sample::PrintValue() {
cout << 2 * value + mv << endl;
}
void Print(const Sample & o) {
o.PrintValue(); // 若PrintValue()非const则编译错 因为o是const的
}
const Sample Obj; // 常量对象
Obj.SetValue(); // 常量对象上可以使用常量成员函数
Obj.PrintValue(); // 重载,自动使用常量成员函数
Sample Obj2;
Obj2.SetValue(); // 非常量对象上也可以使用常量成员函数
Obj2.PrintValue(); // 重载,自动使用非常量成员函数
运算符重载
基本概念
- 运算符重载的实质是函数重载,格式:
返回值类型 operator 运算符(形参表){ … } - 可以重载为普通函数,也可以重载为成员函数
- 把含运算符的表达式转换成对运算符函数的调用
- 把运算符的操作数转换成运算符函数的参数
- 重载为成员函数时,参数个数为运算符目数减一
- 重载为普通函数时,参数个数为运算符目数
- 运算符被多次重载时,根据实参的类型决定调用哪个运算符函数
- C++不允许定义新的运算符
- 运算符重载不改变运算符的优先级
- 以下运算符不能被重载:“.”、“.*”、“::”、“?:”、sizeof
- 重载运算符()、[]、->或者赋值运算符=时,运算符重载函数必须声明为类的成员函数
重载基本算数运算符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Complex {
public:
double real, imag;
Complex(double r = 0.0, double i = 0.0): real(r), imag(i) {}
const Complex operator- (const Complex& c);
};
//重载为成员函数时 参数个数为运算符目数减一 -是双目 2-1=1
const Complex Complex::operator-(const Complex& c) {
return Complex(real - c.real, imag - c.imag);
}
//重载为普通函数时 参数个数为运算符目数
const Complex operator+( const Complex & a, const Complex & b) {
return Complex( a.real+b.real,a.imag+b.imag);
}
Complex a(4,4),b(1,1),c;
c = a + b; // 等价于c=operator+(a,b);
c = a - b; // 等价于c=a.operator-(b)
重载赋值运算符
赋值运算符“=”只能重载为成员函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class String {
private:
char * str;
public:
String() : str(new char[1]) {
str[0] = 'a';
}
const char* c_str() {
return str;
}
String & operator= (const String& s) {
if (this == &s) {
return *this;
}
delete [] str;
str = new char[strlen(s.str) + 1];
strcpy(str, s.str);
return *this;
}
String & operator= (const char * s) {
delete [] str;
str = new char[strlen(s)+1];
strcpy( str, s);
return * this;
};
String (const String & s) { //拷贝构造函数 需要的参数是String
if (this != &s) {
str = new char[strlen(s.str) + 1];
strcpy(str, s.str);
}
}
~String() {
delete [] str;
}
};
String s;
s = "Good Luck" ; // 赋值语句不会调用复制构造函数,等价于s.operator=("Good Luck");
String s2(s); // 这样的初始化语句会调用复制构造函数,这个是对的
String s2 = s; // 这样的初始化语句会调用复制构造函数,这个是对的
//String s2("hello!"); // 这样的初始化语句会调用复制构造函数,这个是错的,参数错误
//String s2 = "hello!"; // 这样的初始化语句会调用复制构造函数,这个是错的,参数错误
s2 = s; // 赋值语句不会调用复制构造函数,等价于s2.operator=(s);
返回值String &的原因:可以做左值
(1)a = b = c 等价于 a.operator=(b.operator=(c))
不管返回值有没有&效果都是a=c,b=c
(2)(a=b)=c 等价于 (a.operator=(b)).operator=(c)
如果带&,a=b之后a=c,最后效果是a=c
如果不带&,效果就是a=b
重载为友元函数
- 重载为成员函数时,参数个数为运算符目数减一
- 重载为普通函数时,参数个数为运算符目数
- 重载为普通函数时,如果不能访问类的私有成员,则需要将运算符重载为友元函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Complex {
private:
double real, imag;
public:
Complex(double r, double i): real(r), imag(i) {}
// Complex c; 可以 c+5 相当于c.operator+(5);
const Complex operator+ (double r);
// Complex c; 可以 5+c 相当于operator+(5,c);
friend const Complex operator+( double r, const Complex & b);
};
const Complex operator+( double r, const Complex & b) {
return Complex(b.real, b.imag+r);
}
重载[]运算符
“[]”只能重载为成员函数。
自定义数组类型,重载[]以支持根据下标访问数组元素
因为数组支持n = a[i] 和a[i] = 4,所以重载函数应该返回int &这样的引用类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
class CArray {
private:
int size;
int * ptr;
public:
CArray(int len=0) : size(len) {
if( len == 0)
ptr = NULL;
else
ptr = new int[len];
}
CArray(const CArray& c) { // 复制构造函数
if (c.ptr == NULL) {
ptr = NULL;
size = 0;
return;
}
ptr = new int[c.size];
memcpy(ptr, c.ptr, sizeof(int)*c.size);
size = c.size;
}
~CArray() {
if( ptr ) delete [] ptr;
}
void push_back(int v) {
if(ptr) { // 原本不为空 追加一个
int * tmpPtr = new int[size+1]; // 重新分配空间
memcpy(tmpPtr,ptr,sizeof(int)*size); // 拷贝原数组内容
delete [] ptr;
ptr = tmpPtr;
}
else { // 数组本来是空的
ptr = new int[1];
}
ptr[size++] = v; // 加入新的数组元素
}
CArray& operator= (const CArray& a) { // 重载赋值运算符= 返回值是& 可以支持连等
if (ptr == a.ptr) {
return * this;
}
if (a.ptr == NULL) {
if(ptr) delete [] ptr;
ptr = NULL;
size = 0;
return * this;
}
if (size < a.size) { // 原来的空间不够大 需要申请
if (ptr) delete [] ptr;
ptr = new int[a.size];
}
memcpy(ptr, a.ptr, sizeof(int)*a.size);
size = a.size;
return * this;
}
int length() { return size;}
int& operator[] (int i) { // 重载[] 返回值是& 可以支持a[i]=10;
return ptr[i];
}
};
CArray a;
a.push_back(1);
a.push_back(2);
CArray a2;
a2 = a; //重载了=
a[0] = 100; //重载了[]
CArray a3(a); //实现了复制构造函数
重载输入输出运算符
只能重载为全局函数
cout本身就实现了重载:
cout 是在 iostream 中定义的,ostream 类的对象
支持 cout<<5; cout<<“hahaha”; 也支持cout<<5<<“hahaha”;
说明重载函数返回的是ostream &类型。
1
2
3
4
5
6
7
8
9
10
ostream & ostream::operator<<(int n)
{
// 输出n的代码
return * this;
}
ostream & ostream::operator<<(const char * s )
{
// 输出s的代码
return * this;
}
由于没有办法去修改ostream 类的代码,为了实现我们自定义的类的重载输出,需要将”«“重载为全局函数,函数的第一个参数以及返回值的类型都是ostream &,且由于全局函数一般无法访问类内的对象,所以需要定义为友元函数。
cin对象同理,需要重载“»”运算符为全局函数,函数的第一个参数以及返回值的类型都是istream &。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Complex {
private:
double real, imag;
public:
Complex(double r, double i): real(r), imag(i) {}
friend ostream& operator<< (ostream & os, const Complex & c);
friend istream& operator>> (istream & is, Complex & c);
};
// 输出函数一般不修改c,所以加const
ostream& operator<< (ostream & os, const Complex & c) {
os << c.real << "+" << c.imag << "i"; // 以"a+bi"
return os;
}
// 把输入转成Complex类型,通过引用的作用返回回去
istream& operator>> (istream & is, Complex & c) {
string s;
is >> s; // 将"a+bi" 作为字符串读入,中间不能有空格
int pos = s.find("+",0);
string sTmp = s.substr(0,pos); // 分离出代表实部的字符串
c.real = atof(sTmp.c_str()); //atof 库函数能将const char* 指针成 指向的内容转换成 float
sTmp = s.substr(pos+1, s.length()-pos-2); // 分离出代表虚部的字符串
c.imag = atof(sTmp.c_str());
return is;
}
重载强制类型转换运算符
- 相当于重载
double、int这类的运算符,不同的是重载函数不写返回值类型。 - 一个类不能定义多个这类的重载函数,否则出现二义性。
- 如果定义了,则默认调用强制类型转换函数,不需要显式的
(double)c。 - 如果加
explicit则需要显式的做转换(double)c。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Complex {
private:
double real, imag;
public:
Complex(double r, double i): real(r), imag(i) {}
void describe() const {
cout << real << "+" << imag << "i" << endl; // 以"a+bi"
}
// explicit operator double() { // 加explicit则需要显示转换 (double)c
// return real;
// }
operator double() { // 默认调用强制类型转换 重载double
return real;
}
// operator int() { // 默认调用强制类型转换 重载int
// return (int)real;
// }
};
int main() {
Complex c(10.2,4.2);
cout << c << endl; //10.2
cout << (double)c << endl; //10.2
double n = 2 + c;
cout << n << endl; //12.2
cout << 2+c << endl; //12.2
}
重载自增自减运算符
自增运算符++、自减运算符–有前置/后置之分。为了区分所重载的是前置运算符还是后置运算符,C++规定:
前置运算符作为一元运算符重载。
重载为成员函数:
T & operator++();
T & operator--();
重载为全局函数:
T1 & operator++(T2);
T1 & operator--(T2);
后置运算符作为二元运算符重载,多写一个没用的参数。(否则仅返回值不同不构成重载,出现二义性)
重载为成员函数:
T operator++(int);
T operator--(int);
重载为全局函数:
T1 operator++(T2,int);
T1 operator--(T2,int);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class Cdmo {
private:
int n;
public:
Cdmo (int n_=0) : n(n_) {}
// 重载前置运算符 ++a --a
Cdmo& operator++() {
n++;
return *this; //++a a本身变了
}
// 重载后置运算符 a++ a--
Cdmo operator++(int) {
Cdmo tmp(*this); //用temp保留*this
n++;
return tmp;
}
// 重载强制类型转换运算符int,用于输出
operator int() {
return n;
}
// 另一种方式 重载成全局函数
friend Cdmo& operator--(Cdmo & c);
friend Cdmo operator--(Cdmo & c, int);
};
Cdmo& operator--(Cdmo & c) {
c.n--;
return c;
}
Cdmo operator--(Cdmo & c, int) {
Cdmo tmp(c);
c.n--;
return tmp;
}
Cdmo d(5);
cout << (d++); // 输出5 因为重载了强制类型转换运算符,所以可以直接输出!
cout << d; // 输出6
重载()运算符
“()”只能重载为成员函数,类重载()可以成为函数对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class CMyAverage {
public:
double operator () ( int a1, int a2, int a3 ) {
//重载 () 运算符
return (double)(a1+a2+a3) / 3;
}
};
class MyLess {
public:
bool operator()( const int & c1, const int & c2 )
{
return (c1 % 10) < (c2 % 10);
}
};
// 函数对象
CMyAverage average;
cout << average(3,2,3) << endl; //函数对象,用起来看上去像函数调用
cout << average.operator()(3,2,3) << endl; //和上一句是等价的 operator()是一个成员函数
继承
父类/基类
子类/派生类
public继承
- 格式:
class 派生类 :public 基类 {...},且支持多继承。 - 支持父类指针指向子类对象、父类引用引用子类对象、将子类对象赋值给父类对象。
- 派生类拥有基类的全部成员函数和成员变量,不论是private、protected、public,但是在派生类的各个成员函数中,不能访问基类中的private成员。
- 派生类对象的体积等于基类对象的体积加上派生类对象自己的成员变量的体积。
- 派生类对象中,包含着基类对象,而且基类对象的存储位置位于派生类对象新增的成员变量之前。
- 派生类可以定义和基类成员同名的成员,叫覆盖。在派生类中访问这类成员时,缺省的情况是访问派生类中定义的成员。要在派生类中访问由基类定义的同名成员,要使用
基类名::成员名 - 派生类使用初始化列表初始化基类,如果基类有无参构造函数,则派生类的构造函数可以不带初始化列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class Bug {
private :
int nLegs; int nColor;
public:
int nType;
Bug ( int legs, int color) : nLegs(legs), nColor(color) { }
void PrintBug (){ cout << "Bug" << endl; }
};
class FlyBug: public Bug { // public继承 可以多继承
private:
int nWings;
public:
FlyBug(int legs, int color, int wings) :
Bug(legs, color), nWings(wings) { } // 初始化列表
void PrintBug () { // 覆盖
Bug::PrintBug(); // 调用父类方法
cout << "FlyBug" << endl;
}
};
int main() {
Bug bug(1,2);
FlyBug fbug(1,2,3);
fbug.PrintBug();
//public继承 可以进行以下方法
Bug bug2 = fbug;
Bug& rbug = fbug;
Bug* pbug = &fbug;
}
- 基类的
private成员只能被基类的成员函数、友元函数访问。 - 基类的
public成员能被所有函数访问。 - 基类的
protected成员只能被基类的成员函数、友元函数以及派生类的成员函数访问,但是派生类的成员函数只可以访问当前对象的基类的保护成员。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Father {
private: int nPrivate;
public: int nPublic;
protected: int nProtected;
}
class Son :public Father {
void AccessFather () {
nPublic = 1; // ok;
nPrivate = 1; // wrong
nProtected = 1; // OK,访问从基类继承的protected成员
Son f;
//f.nProtected = 1; //wrong ,f不是当前对象
}
}
int main(){
Father f; Son s;
f.nPublic = 1; //ok
f.nProtected = 1; //error
f.nPrivate = 1; //error
s.nPublic = 1; //ok
s.nProtected = 1; //error
s.nPrivate = 1; //error
}
protected继承
- 基类的public成员和protected成员成为派生类的protected成员。
- 不支持父类指针指向子类对象、父类引用引用子类对象、将子类对象赋值给父类对象。
private继承
- 基类的public成员成为派生类的private成员。
- 基类的protected成员成为派生类的不可访问成员。
- 不支持父类指针指向子类对象、父类引用引用子类对象、将子类对象赋值给父类对象。
派生类的构造与析构
在创建派生类的对象时:
- 先执行基类的构造函数,用以初始化派生类对象中从基类继承的成员。
- 再执行成员对象类的构造函数,用以初始化派生类对象中成员对象。(封闭类的规则)
- 最后执行派生类自己的构造函数。
因为调用派生类构造函数之前先调用基类的构造函数,所以派生类需要使用初始化列表初始化基类,如果基类有无参构造函数,则派生类的构造函数就可以不带初始化列表。
在派生类对象消亡时:
- 先执行派生类自己的析构函数。(封闭类的规则)
- 再依次执行各成员对象类的析构函数。
- 最后执行基类的析构函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
class Base {
public:
int n;
Base(int i):n(i) { // 这里可以不用初始化列表
cout << "Base " << n << " constructed" << endl;
}
~Base() {
cout << "Base " << n << " destructed" << endl;
}
};
class Derived:public Base
{
public:
Derived(int i):Base(i) {
cout << "Derived constructed" << endl;
}
Derived():Base(10) {
cout << "Derived constructed" << endl;
}
~Derived() {
cout << "Derived destructed" << endl;
}
};
class MoreDerived:public Derived {
public:
MoreDerived(int i) { // 不带初始化列表 因为基类有无参构造
cout << "More Derived constructed" << endl;
}
MoreDerived() { // 不带初始化列表 因为基类有无参构造
cout << "More Derived constructed" << endl;
}
~MoreDerived() {
cout << "More Derived destructed" << endl;
}
};
int main()
{
MoreDerived Obj(20);
return 0;
}
// 输出顺序为:
Base 10 constructed
Derived constructed
More Derived constructed
More Derived destructed
Derived destructed
Base 10 destructed
多态
虚函数
- 在类的定义中,前面有
virtual关键字的成员函数就是虚函数。 virtual关键字只用在类定义里的函数声明中,写函数体时不用。- 不允许以虚函数作为构造函数。
多态的表现形式
主要体现在派生类和基类有同名虚函数的时候,根据指针或引用的具体内容判断调用哪个函数。
-
派生类的指针可以赋给基类指针。
通过基类指针调用基类和派生类中的同名虚函数时:
(1)若该指针指向一个基类的对象,那么被调用的是基类的虚函数;
(2)若该指针指向一个派生类的对象,那么被调用的是派生类的虚函数。
通过基类指针调用基类和派生类中的同名非虚函数时:直接调用基类的函数。
-
派生类的对象可以赋给基类引用。
通过基类引用调用基类和派生类中的同名虚函数时:
(1)若该引用引用的是一个基类的对象,那么被调用是基类的虚函数;
(2)若该引用引用的是一个派生类的对象,那么被调用的是派生类的虚函数。
通过基类引用调用基类和派生类中的同名非虚函数时:直接调用基类的函数。
- 直接把子类对象赋值给父类对象,而不使用指针或者引用,不属于多态
- 在非构造函数、非析构函数的成员函数中调用虚函数,属于多态
- 在构造函数和析构函数中调用虚函数,不属于多态。编译时即确定调用的函数是自己的类或基类中定义的函数,不会等到运行时才决定调用自己的还是派生类的函数。
- 派生类中和基类中的虚函数同名同参数表的函数,不加virtual也自动成为虚函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
class Base {
public:
virtual void a() {
cout << "Base-a" << endl;
}
void b() {
cout << "Base-b" << endl;
}
void c() {
a();
b();
}
};
class Derived:public Base {
public :
virtual void a() { // 子类的virtual可加可不加
cout << "Drived-a" << endl;
}
void b() { // 虽然跟基类同名同参数表,但是基类的b()不是虚函数,所以这个b()也不是
cout << "Drived-b" << endl;
}
};
int main() {
Base b; //父类直接调用,调用的全是父类的
b.a();
b.b();
b.c();
cout << "--------------" << endl;
Derived o;
o.a(); //virtual的 实现多态 调用自己的
o.b(); //子类对象直接调用 没有virtual 但是调用的是自己的
o.c(); //c()继承自父类 c()中调用a()方法virtual的是多态的;调用b()不是virtual是调用父类的
cout << "--------------" << endl;
//直接父类=子类的赋值 不能实现多态 调用的全是父类的
Base b2 = o;
b2.a();
b2.b();
b2.c();
cout << "--------------" << endl;
//指针和引用可以虚函数的实现多态
Base * p = & o;
p->a(); //a()是virtual的 多态
p->b(); //b()不是virtual的 无法实现多态
p->c(); //c()调用a()是多态的 调用b()是父类的
cout << "--------------" << endl;
Base & r = o;
r.a(); //a()是virtual的 多态
r.b(); //b()不是virtual的 无法实现多态
r.c(); //c()调用a()是多态的 调用b()是父类的
cout << "--------------" << endl;
return 0;
}
虚析构函数
- 通过基类的指针删除派生类对象时,通常情况下只调用基类的析构函数。
- 为了先调用派生类的析构,再调用基类的析构,可以在基类的析构函数前加
virtual,派生类不用加。 - 一般来说,一个类如果定义了虚函数,则应该将析构函数也定义成虚函数。
- 一个类如果打算作为基类使用,应该将析构函数定义成虚函数。
- 不允许以虚函数作为构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class son {
public:
son() {cout<<"hi from son"<<endl;}
virtual ~son() {cout<<"bye from son"<<endl;} //加virtual才能先析构子类再析构父类
};
class grandson : public son {
public:
grandson() {cout<<"hi from grandson"<<endl;}
~grandson(){cout<<"bye from grandson"<<endl;}
};
int main(){
son *pson;
pson = new grandson(); //先构造父类 后构造子类 这个是正常的
delete pson; //父类析构函数加virtual才能先析构子类再析构父类,否则只析构父类
grandson gs; //普通的子类对象,先构造父类后构造子类,先析构子类再析构父类,不存在问题。
return 0;
}
纯虚函数和抽象类
- 纯虚函数是没有函数体的虚函数。格式为
virtual void f() = 0; - 包含纯虚函数的类叫抽象类。
- 抽象类只能作为基类来派生新类使用,不能创建抽象类的对象。
- 抽象类的指针和引用可以指向由抽象类派生出来的类的对象。(也就是支持多态)
- 在抽象类的成员函数内可以调用纯虚函数,但是在构造函数或析构函数内部不能调用纯虚函数。
- 如果一个类从抽象类派生而来,那么当且仅当它实现了基类中的所有纯虚函数,它才能成为非抽象类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class A { // 抽象类
private:
int a;
public:
A() {
//Print(); // 构造函数和析构函数中不能调用纯虚函数
fun(); // 构造函数和析构函数中可以调用普通函数
}
virtual void Print() = 0; // 纯虚函数
virtual void Set(int n) = 0; // 纯虚函数
void fun() { cout << "fun" << endl; }
void fun2() { Print(); } // 普通成员函数中可以调用纯虚函数
};
class B : public A { // B继承自抽象类A,实现了A中全部的纯虚函数变成非抽象类
virtual void Print() {
cout << "bbb" << endl;
}
virtual void Set(int n) { }
};
int main(){
//A a; 抽象类不可以有对象
A* pa;
//A* pa = new A; 抽象类不可以有对象
B b; // 构造父类的时候 输出fun
b.fun(); // 继承自A 输出fun
b.fun2(); // 继承自A 调用Print()是多态,输出bbb
A& r = b; // 多态 虽然A是抽象类
r.fun2(); // 调用Print()是多态,输出bbb
pa = &b; // 多态 虽然A是抽象类
pa->fun2(); // 调用Print()是多态,输出bbb
return 0;
}
输入和输出
相关类
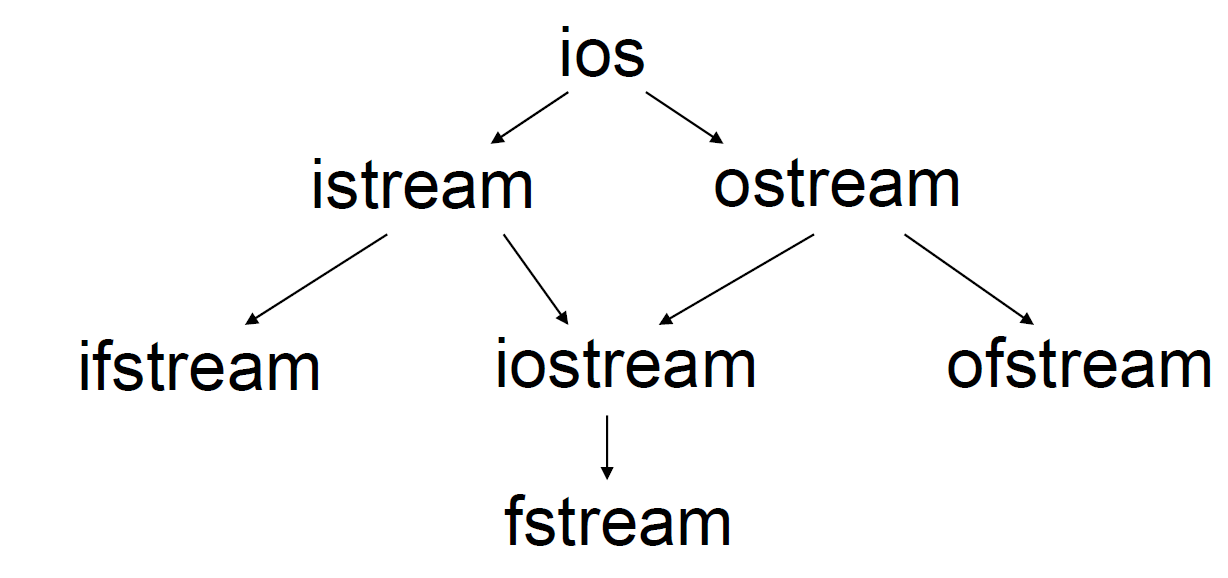
istream是用于输入的流类,cin就是该类的对象。ostream是用于输出的流类,cout就是该类的对象。ifstream是用于从文件读取数据的类。ofstream是用于向文件写入数据的类。iostream是既能用于输入,又能用于输出的类。fstream是既能从文件读取数据,又能向文件写入数据的类。
标准流对象
-
cin对应于标准输入流,用于从键盘读取数据,也可以被重定向为从文件中读取数据。 -
cout对应于标准输出流,用于向屏幕输出数据,也可以被重定向为向文件写入数据。 -
cerr对应于标准错误输出流,用于向屏幕输出出错信。 -
clog对应于标准错误输出流,用于向屏幕输出出错信息。cerr和clog的区别在于cerr不使用缓冲区,直接向显示器输出信息;而输出到clog中的信息先会被存放在缓冲区,缓冲区满或者刷新时才输出到屏幕。
输入输出重定向
1
2
freopen("in.txt", "r", stdin); // 将标准输入cin被改为从in.txt中读取数据
freopen("test.txt", "w", stdout); // 将标准输出cout重定向到test.txt文件
istream类成员函数
-
istream & getline(char * buf, int bufSize);从输入流中读取
bufSize-1个字符到缓冲区buf,或读到碰到‘\n’为止(哪个先到算哪个)。 -
istream & getline(char * buf, int bufSize,char delim);从输入流中读取
bufSize-1个字符到缓冲区buf,或读到碰到delim字符为止(哪个先到算哪个)。- 两个函数都自动在
buf中读入数据的结尾添加‘\0’。 ‘\n’或delim都不会被读入buf,但会被从输入流中取走。- 如果输入流中
‘\n’或delim之前的字符个数达到或超过了bufSize个,就导致读入出错,其结果就是:虽然本次读入已经完成,但是之后的读入就都会失败了。 - 用
if(!cin.getline(…))判断输入是否结束。
- 两个函数都自动在
-
bool eof();判断输入流是否结束。
-
int peek();返回下一个字符,但不从流中去掉。
-
istream & putback(char c);将字符
ch放回输入流。 -
istream & ignore( int nCount = 1, int delim = EOF );从流中删掉最多
nCount个字符,遇到EOF时结束。
流操纵算子
使用流操纵算子需要 #include
-
整数流的基数:流操纵算子
dec,oct,hexcout « hex « n « ” “ « dec « n « ” “ « oct « n « endl;(16/10/8进制)
-
浮点数的精度(precision,setprecision)
precision是成员函数:cout.precision(5);setprecision是流操作算子:cout << setprecision(5);功能:
(1)指定输出浮点数的有效位数(非定点方式输出时)
cout << setprecision(6) << x << endl;浮点数输出最多6位有效数字(2)指定输出浮点数的小数点后的有效位数(定点方式输出时)
cout << setiosflags(ios::fixed) << setprecision(6) << x << endl;setiosflags(ios::fixed)是以小数点位置固定的方式输出。resetiosflags(ios::fixed)是取消以小数点位置固定的方式输出。 -
设置域宽(setw,width)
cin >> setw(4);或者cin.width(5);cout << setw(4);或者cout.width(5);功能:
设置每次输入输出的数据宽度。
宽度设置有效性是一次性的,在每次读入和输出之前都要设置宽度。
-
用户自定义的流操纵算子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
ostream & tab(ostream &output) { // 自定义流操纵算子
return output << '\t';
}
int main() {
int n = 141;
//1) 分别以十六进制、十进制、八进制先后输出 n
cout << "1) " << hex << n << " " << dec << n << " " << oct << n << endl;
double x = 1234567.89,y = 12.34567;
//2) 保留5 位有效数字
cout << "2) " << setprecision(5) << x << " " << y << " " << endl;
//3) 保留小数点后面5 位
cout << "3) " << fixed << setprecision(5) << x << " " << y << endl ;
//4) 科学计数法输出,且保留小数点后面5 位
cout << "4) " << scientific << setprecision(5) <<x << " " << y << endl ;
//5) 非负数要显示正号,输出宽度为12 字符,宽度不足则用'*' 填补
cout << "5) " << showpos << fixed << setw(12) << setfill('*') << 12.1 << endl;
//6) 非负数不显示正号,输出宽度为12 字符,宽度不足则右边用填充字符填充
cout << "6) " << noshowpos << setw(12) << left << 12.1 << endl;
//7) 输出宽度为12 字符,宽度不足则左边用填充字符填充
cout << "7) " << setw(12) << right << 12.1 << endl;
//8) 宽度不足时,负号和数值分列左右,中间用填充字符填充
cout << "8) " << setw(12) << internal << -12.1 << endl;
cout << "9) " << 12.1 << endl;
cout << "10) " << "aa" << tab << "bb" << endl;
return 0;
}
1) 8d 141 215
2) 1.2346e+006 12.346
3) 1234567.89000 12.34567
4) 1.23457e+006 1.23457e+001
5) ***+12.10000
6) 12.10000****
7) ****12.10000
8) -***12.10000
9) 12.10000
10) aa bb
文件读写
文件读写需要 #include
可以将顺序文件看作一个有限字符构成的顺序字符流,然后像对cin, cout 一样的读写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <fstream> //头文件
// 打开文件
ifstream srcFile("in.txt",ios::in);
ofstream destFile("out.txt",ios::out);
// 也可以先创建ofstream对象,再用open函数打开
ofstream fout;
fout.open("test.out",ios::out|ios::binary);
// 判断打开是否成功:
if(!fout) {...}
// 流操作
srcFile >> x;
destFile << x;
// 关闭文件
destFile.close();
srcFile.close();
- ios::in —> 从文件输入
- ios::out —> 输出到文件, 删除原有内容
- ios::app —> 输出到文件, 保留原有内容,总是在尾部添加
- ios::binary —> 以二进制文件格式打开文件
文件名可以给出绝对路径,也可以给相对路径。没有交代路径信息,就是在当前文件夹下找文件。
文件读写指针
标识文件操作的当前位置,该指针在哪里,读写操作就在哪里进行。
1
2
3
4
5
6
7
8
9
10
11
12
13
long location = fout.tellp(); // 取得写指针的位置
location = 10;
fout.seekp(location); // 将写指针移动到第10个字节处,location可以为负值
fout.seekp(location,ios::beg); // 从头数location
fout.seekp(location,ios::cur); // 从当前位置数location
fout.seekp(location,ios::end); // 从尾部数location
long location = fin.tellg(); // 取得读指针的位置
location = 10L;
fin.seekg(location); // 将读指针移动到第10个字节处,location可以为负值
fin.seekg(location,ios::beg); // 从头数location
fin.seekg(location,ios::cur); // 从当前位置数location
fin.seekg(location,ios::end); // 从尾部数location
二进制文件读写
-
istream& read (char* s, long n);将文件读指针指向的地方的n个字节内容,读入到内存地址s,然后将文件读指针向后移动n字节。
以
ios::in方式打开文件时,文件读指针开始指向文件开头。 -
ostream& write (const char* s, long n);将内存地址s处的n个字节内容,写入到文件中写指针指向的位置,然后将文件写指针向后移动n字节。
以
ios::out方式打开文件时,文件写指针开始指向文件开头。以
ios::app方式打开文件时,文件写指针开始指向文件尾部。
1
2
3
4
5
6
7
8
9
10
ofstream fout("some.dat", ios::out | ios::binary);
int x = 120;
fout.write( (const char *)(&x), sizeof(int) ); //&x 是取x的内存地址
fout.close();
ifstream fin("some.dat", ios::in | ios::binary);
int y;
fin.read((char*) & y, sizeof(int));
fin.close();
cout << y <<endl;
模板
函数模板
- 格式:
template <class 类型参数1,class 类型参数2,……> 返回值类型 模板名 (形参表){ 函数体 }; template <class 类型参数1,class 类型参数2,……>叫做类型参数表。- 编译器会根据参数自动实例化出相应的模板函数。
1
2
3
4
5
6
7
template <class T>
void Swap(T & a, T & b) // 模板函数
{
T tmp = a;
a = b;
b = tmp;
}
- 函数模板可以重载,只要它们的形参表或类型参数表不同即可。
- 匹配模板函数时,不进行类型自动转换。
- 在有多个函数和函数模板名字相同的情况下,先找参数完全匹配的普通函数(非模板函数),再找参数完全匹配的模板函数,再找实参数经过自动类型转换后能够匹配的普通函数,还找不到就报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 形参表一样 但是参数类型表不一样 也是重载
template<class T>
void print(T arg1, T arg2) {
cout<< arg1 << " a "<< arg2<<endl;
}
template<class T,class T2> // 定义了T2 但是没用
void print(T arg1, T arg2) { // 全是T
cout<< arg1 << " b "<< arg2<<endl;
}
print(1,1);
print(1.1,1.1);
// print(1,1.1); 匹配模板函数时,不进行类型自动转换 没有int,double对应的模板
- 函数模板可以显式的具体化,格式:
template <> 返回值类型 模板函数名(实际参数表){函数体}。应用于针对特定的类型参数,不希望调用编译器自动生成的代码的时候。 - 函数模板可以显式的实例化,格式:
template 返回值类型 模板函数名<实际类型参数>(实际参数表);。注意不能写函数体。 - 调用函数模板时,优先调用参数完全匹配的非模板函数,可以强制调用模板函数,在函数名后加<>或<实际类型参数>即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct node{
int a,b,c;
};
template <> void Swap(node & a, node & b) // 模板的显式具体化
{
int t = a.a;
a.a = b.b;
b.b = t;
t = a.b;
a.b = b.a;
b.a = t;
}
template void Swap<char>(char & a, char & b); // 模板的显式实例化 不能写函数体
int x=2;y=2;
Swap<int>(x,y); // 强制调用模板函数
Swap<>(x,y); // 强制调用模板函数
- 函数模板可以做类的友元。
1
2
3
4
5
6
7
8
class A
{
int v;
public:
A(int n):v(n) { }
template<class T>
friend void print(T arg1, T arg2); // 函数模板做类的友元
};
类模板
- 定义类时加上类型参数就得到类模板。
- 编译器由类模板生成类的过程叫类模板的实例化。由类模板实例化得到的类叫模板类。
- 格式:
template <class 类型参数1,class 类型参数2,……> class 类模板名{成员函数和成员变量}; template <class 类型参数1,class 类型参数2,……>叫做类型参数表。- 类模板中的成员函数:
template <class 类型参数1,class 类型参数2,……> 返回值类型 类模板名<类型参数名列表>::成员函数名(参数表) {函数体}。 - 类模板中的成员函数可以是函数模板。
- 用类模板定义对象:
类模板名 <真实类型参数表> 对象名(构造函数实参表); - 同一个类模板的两个模板类是不兼容的。
- 类模板的类型参数表中可以出现非类型参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
template <class T1, class T2>
class Pair {
public:
T1 key;
T2 value;
Pair(T1 k, T2 v): key(k), value(v) { }
bool operator< (const Pair<T1,T2> &p) const; // 成员函数的声明
template <class T3> // 成员函数模板
void func(T3 t) {
cout << "hahaha " << t << endl;
}
};
// 成员函数的实现
template <class T1, class T2>
bool Pair<T1, T2>::operator< (const Pair<T1, T2> & p) const {
return key < p.key;
}
// 实例化出一个类 Pair<string,int>
Pair<string,int> student("Tom",19);
// 调用成员函数模板,成员函数模板被实例化
student.func("Liu");
Pair<string,int> *p;
Pair<string,double> a("LLL", 20.99);
//p = & a; //wrong
// 非类型参数
template <class T, int size>
class CArray {
T array[size];
public:
void Print() {
for( int i = 0;i < size; ++i)
cout << array[i] << endl;
}
};
类模板和静态成员
- 类模板中可以定义静态成员,从该类模板实例化得到的所有类,都包含这个静态成员。
- 这些模板类的静态成员不是同一个,同一种实例化方式得到的模板类的所有对象共享同一个静态成员。
- 类模板的静态成员变量也需要显式的初始化,需要写清楚变量类型。
- 每一种实例化方式,都要写自己的对静态成员初始化的语句。格式:
template<> 静态变量类型 类模板名<真实类型参数表>::静态变量名=..;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template <class T>
class A
{
private:
static int count; //静态成员变量
public:
A() { count ++; }
~A() { count -- ; };
A( A & ) { count ++ ; }
static void PrintCount() { cout << count << endl; } //静态成员函数
};
template<> int A<int>::count = 0; // 静态成员变量需要显式的初始化 需要写清楚变量类型
template<> int A<double>::count = 0;
A<int> ia;
A<int> ib;
A<double> da;
ia.PrintCount(); // 输出2 A<int>是一个模板类 ia,ib是同一个类型 count是属于类的
ib.PrintCount(); // 输出2
da.PrintCount(); // 输出1
类模板和继承
(1)类模板从类模板派生
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template <class T1,class T2>
class A {
T1 v1; T2 v2;
};
template <class T1,class T2>
class B : public A<T2,T1> { // 类模板从类模板派生
T1 v3; T2 v4;
};
template <class T>
class C : public B<T,T> { // 类模板从类模板派生
T v5;
};
(2)类模板从模板类派生
1
2
3
4
template <class T>
class D : public A<int,double> { // 类模板从模板类派生
T v;
};
(3)类模板从普通类派生
所有从类模板实例化得到的模板类,都以普通类为基类。
1
2
3
4
5
6
7
8
class E {
int v1;
};
template <class T>
class F : public E { // 类模板从普通类派生 所有从F实例化得到的类,都以E为基类
T v;
};
(4)普通类从模板类派生
1
2
3
class G : public A<int, double> { // 普通类从模板类派生
double v;
};
类模板和友元
(1)函数、类、类的成员函数作为类模板的友元
任何从类模板实例化来的模板类 ,都有这些友元。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void Func() { }
class A { };
class B
{
public:
void Func() { }
};
template <class T> // 函数、类、类的成员函数作为类模板的友元
class Tmp
{
friend void Func();
friend class A;
friend void B::Func();
}; // 任何从Tmp实例化来的类 ,都有以上三个友元
(2)函数模板作为类模板的友元
- 任意从这个函数模板实例化出的函数,都是任意从类模板实例化出的模板类的友元。
- 但是自己写的函数,即使它符合这个函数模板,也不会是这些模板类的友元。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template <class T1,class T2>
class Pair // 类模板
{
private:
T1 key;
T2 value;
public:
Pair(T1 k,T2 v):key(k),value(v) { };
// 函数模板作为类模板的友元
template <class T3,class T4>
friend ostream & operator<< ( ostream & o, const Pair<T3,T4> & p);
};
template <class T3,class T4>
ostream & operator<< ( ostream & o, const Pair<T3,T4> & p) {
o << "(" << p.key << "," << p.value << ")" ;
return o;
}
(3)类模板作为类模板的友元
如果AA是BB的友元,则任何从AA模版实例化出来的类,都是任何BB实例化出来的类的友元。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template <class T>
class BB {
T v;
public:
BB(T n) : v(n) { }
//类模板作为类模板的友元
template <class T2>
friend class AA;
//任何从AA模版实例化出来的类,都是任何BB实例化出来的类的友元
};
template <class T>
class AA {
public:
void Func( ) {
BB<int> o(10);
cout << o.v << endl; // AA是BB的友元,AA的成员函数可以访问BB的私有成员。
}
};
string类
string类是模板类
使用string类要包含头文件 #include <string>
对象初始化
1
2
3
4
5
6
7
8
9
string s1("Hello");
string month = "March";
string s2(8,'x'); // 就是8个x,即xxxxxxxx
string s3(s2, 2, 4); // s3=s2从2开始长度为4的子串
// 不能用数字或者字符类型进行初始化
// 但是可以用字符类型进行赋值
// string s3='n'; 错误
string s3;
s3 = 'n';
流读取运算符
1
2
cin >> stringObject;
getline(cin ,s);
长度
1
s1.length()
赋值
1
2
3
4
5
6
7
8
string s4,s5;
s4=s1; // 赋值
s5.assign(s4); // 赋值
s5.assign(s4,1,3); // 下标为1的字符开始复制3个字符
s1.assign(4,'x'); // 4个x
s1.assign("1234", 2); // 字符串的前2个字符
s1.assign("1234"); // 整个字符串
s4[1] = 'a'; // 赋值
按下标访问
成员函数at()会做范围检查,如果超出范围,会抛出out_of_range异常,而下标运算符[]不做范围检查
1
2
3
4
s4[1] = 'a';
for(int i=0;i<s1.length();i++)
cout << s1.at(i) << endl;
迭代器
1
2
3
4
s1.begin(); // 指向字符串的第一个字符的正向迭代器
s1.end(); // 指向字符串的末尾(最后一个字符的下一个位置)的正向迭代器
s1.rebegin(); // 指向字符串的最后一个字符的逆向迭代器
s1.rend(); // 指向字符串的开头(第一个字符的前一个位置)的逆向迭代器
连接
1
2
3
4
5
6
// 用 + 运算符连接字符串
s5+=s1;
// 用成员函数 append 连接字符串
s1.append(s2);
// 下标为3开始,s1.size()个字符,如果字符串内没有足够字符,则停止
s2.append(s1, 3, s1.size()); //s1.size(),s1字符数
比较
1
2
3
4
5
6
7
8
// 用关系运算符比较string的大小,返回bool
// ==, >, >=, <, <=, !=
// 用成员函数compare比较string的大小,返回0,1,-1
s1.compare(s2);
s1.compare(1,2,s3); //s1的1开始的2个字符的子串; s3
s1.compare(1,2,s3,0,3); //s1的1开始的2个字符的子串; s3的0开始的3个字符的子串
s1.compare("222");
s1.compare(1,2,"222",2); //s1的1开始的2个字符的子串; "222"长度为2的子串
子串
1
2
// 用成员函数substr
string s6 = s1.substr(3,5); // 下标3开始5个字符
交换
1
2
3
// 用成员函数swap
string ss1("hello world"), ss2("really");
ss1.swap(ss2);
查找
find 可以查找string类型的字符串,char*类型的字符串,char类型的字符。
1
2
3
4
5
6
7
8
9
10
11
12
// find(str) 从前向后查找,找到返回位置下标,否则返回string::npos
// rfind(str) 从后向前查找,找到返回位置下标,否则返回string::npos
string s7("hello world");
s7.find("e"); //从下标0开始
s7.find("l",4); //从下标4开始
s7.find("l",4, 5); //从下标4开始,查找5个字符
s7.find(s1, 4); //从下标4开始
s7.find('l',4); //从下标4开始
// find_first_of(str) 从前向后查找,查找str中任何一个字符第一次出现的地方,如果找到返回找到字母的位置,如果找不到,返回string::npos
// find_last_of(str) 从后向前查找,查找str中任何一个字符第一次出现的地方,如果找到返回找到字母的位置,如果找不到,返回string::npos
// find_first_not_of() 从前向后查找,查找不在str中的字母第一次出现的地方,如果找到,返回找到字母的位置,如果找不到,返回string::npos
// find_last_not_of() 从后向前查找,查找不在str中的字母第一次出现的地方,如果找到,返回找到字母的位置,如果找不到,返回string::npos
删除字符
iterator erase( iterator pos );// 删除pos位置,返回下一个位置的迭代器iterator erase( iterator start, iterator end );// 删除从start到end的所有字符basic_string &erase( size_type index = 0, size_type num = npos );// 删除index开始的num个字符,参数只用index可以删除index后的所有字符,不带有任何参数可以删除所有字符
1
2
3
// 用成员函数erase()
s7.erase(5); // 去掉下标5及之后的字符
s7.erase(); // 删除所有字符
替换字符
-
basic_string &replace( size_type index, size_type num, const basic_string &str );用str中的num个字符替换本字符串中的字符,从index开始
-
basic_string &replace( size_type index1, size_type num1, const basic_string &str, size_type index2, size_type num2 );用str中的num2个字符(从index2开始)替换本字符串中的字符,从index1开始,最多num1个字符
-
basic_string &replace( size_type index, size_type num, const char *str );用str中的num个字符替换本字符串中的字符,从index开始
-
basic_string &replace( size_type index, size_type num1, const char *str, size_type num2 );用str中的num2个字符(从index2开始)替换本字符串中的字符,从index1开始,最多num1个字符
-
basic_string &replace( size_type index, size_type num1, size_type num2, char ch );用str中的num个字符(从index开始)替换本字符串中的字符
-
basic_string &replace( iterator start, iterator end, const basic_string &str );用str中的字符替换本字符串中的字符,迭代器start和end指示范围
-
basic_string &replace( iterator start, iterator end, const char *str );用str中的字符替换本字符串中的字符,迭代器start和end指示范围
-
basic_string &replace( iterator start, iterator end, const char *str, size_type num );用str中的num个字符替换本字符串中的内容,迭代器start和end指示范围
-
basic_string &replace( iterator start, iterator end, size_type num, char ch );用num个ch字符替换本字符串中的内容,迭代器start和end指示范围
1
2
3
// 用成员函数replace()
s1.replace(2,3,"haha"); // 将s1中下标2开始的3个字符换成"haha"
s1.replace(2,3,"haha", 1,2); // 将s1中下标2开始的3个字符换成"haha"中下标1开始的2个字符
插入字符
iterator insert( iterator i, const char &ch );// 迭代器前边插入chbasic_string &insert( size_type index, const basic_string &str );// 在index处插入basic_string &insert( size_type index, const char *str );basic_string &insert( size_type index1, const basic_string &str, size_type index2, size_type num );// 在index处插入一个子串basic_string &insert( size_type index, const char *str, size_type num );basic_string &insert( size_type index, size_type num, char ch );// 插入n个chvoid insert( iterator i, size_type num, const char &ch );// 迭代器前边插入num个chvoid insert( iterator i, iterator start, iterator end );// 迭代器前边插入start-end的串
1
2
3
// 用成员函数insert()
s7.insert(5, s2); // 将s2插入s7下标5的位置
s7.insert(2,s2,5,3); // 将s2中下标5开始的3个字符插入s7下标2的位置
转成C语言的字符串
1
2
3
// 用成员函数c_str(),返回const char* 类型字符串,以'\0'结尾
s1.c_str()
// 用成员函数data(),返回一个char*类型的字符串
拷贝
` size_type copy( char *str, size_type num, size_type index ); `
拷贝自己的num个字符到str中(从索引index开始)。返回值是拷贝的字符数。
1
2
3
4
s1="hello world";
int len = s1.length();
char * p2 = new char[len+1];
s1.copy(p2,5,0); // 从s1的下标0的字符开始制作一个最长5个字符长度的字符串副本并将其赋值给p2。返回值表明实际复制字符串的长度
字符串流处理
用istringstream和ostringstream进行字符串上的输入输出,也称为内存输入输出。
需要 #include
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <string>
#include <iostream>
#include <sstream>
string input("Input test 123 4.7 A");
istringstream inputString(input);
string string1, string2;
int i;
double d;
char c;
inputString >> string1 >> string2 >> i >> d >> c;
// string1="Input" string2="test" i=123 d=4.7 c='A'
long L;
if (inputString >> L) {...} else {...} // 执行else,因为已经空了
ostringstream outputString;
int a = 10;
outputString << "This " << a << "ok" << endl;
cout << outputString.str(); // This 10ok
STL
顺序容器
vector
#include
动态数组:元素在内存连续存放。随机存取任何元素都能在常数时间完成。在尾端增删元素具有较佳的性能(大部分情况下是常数时间)。
deque
#include
双向队列:元素在内存连续存放。随机存取任何元素都能在常数时间完成(但次于vector)。在两端增删元素具有较佳的性能(大部分情况下是常数时间)。
list
#include
双向链表:元素在内存不连续存放。在任何位置增删元素都能在常数时间完成。不支持随机存取。
关联容器
- 元素是排序的
- 插入任何元素,都按相应的排序规则来确定其位置
- 在查找时具有非常好的性能
- 通常以平衡二叉树方式实现,插入和检索的时间都是 O(log(N))
set/multiset
#include
set 即集合。set中不允许相同元素,multiset中允许存在相同的元素。
map/multimap
#include <map>
map中存放的元素有且仅有两个成员变量,一个名为first,另一个名为second,map根据first值对元素进行从小到大排序,并可快速地根据first来检索元素。
map同multimap的不同在于是否允许相同first值的元素。
容器适配器
stack
#include
栈,插入、删除、检索和修改都只能在栈的一端进行,后进先出。
queue
#include
队列,插入只可以在尾部进行,删除、检索和修改只允许从头部进行,先进先出。
priority_queue
include
优先级队列,最高优先级元素总是第一个出列。
迭代器
- 用于指向顺序容器和关联容器中的元素
- 迭代器用法和指针类似
- 有const 和非 const两种
- 通过迭代器可以读取它指向的元素
- 通过非const迭代器还能修改其指向的元素
- 定义一个容器类的迭代器:
容器类名::iterator 变量名;或容器类名::const_iterator 变量名; - 访问一个迭代器指向的元素:
* 迭代器变量名 - 访问一个迭代器指向的元素的某个成员:
迭代器变量名->成员变量名,等效于(*迭代器变量名).成员变量名
双向迭代器
支持:
- ++p, p++ 使p指向容器中下一个元素
- –p, p– 使p指向容器中上一个元素
- *p 取p指向的元素
- p = p1 赋值
- p == p1 , p!= p1 判断是否相等、不等
不支持:
[] ;<; >; <=; >=; p1-p2; p1+2; p1+=2;
也就是for( ii = v.begin(); ii < v.end ();++ii )是错的,不支持<。
随机访问迭代器
- ++p, p++ 使p指向容器中下一个元素
- –p, p– 使p指向容器中上一个元素
- *p 取p指向的元素
- p = p1 赋值
- p == p1 , p!= p1 判断是否相等、不等
- p += i 将p向后移动i个元素
- p -= i 将p向前移动i个元素
- p + i 值为: 指向 p 后面的第i个元素的迭代器
- p - i 值为: 指向 p 前面的第i个元素的迭代器
- p[i] 值为: p后面的第i个元素的引用
- p < p1, p <= p1, p > p1, p>= p1 比较
- p – p1 : p1和p之间的元素个数
容器和对应迭代器
| 容器 | 迭代器 |
|---|---|
| vector | 随机访问迭代器 |
| deque | 随机访问迭代器 |
| list | 双向迭代器 |
| set/multiset | 双向迭代器 |
| map/multimap | 双向迭代器 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
有的算法例如sort, binary_search需要通过随机访问迭代器来访问容器中的元素,那么list以及关联容器就不支持该算法。
vector
对象初始化
1
2
3
4
5
6
7
8
9
10
11
12
vector<int> vec;
vector<int> vec2(100); //vec2 设置size=100
vector<int> v(4,100); //v 有4个元素,都是100
int a[5] = { 1,2,3,4,5 };
vector<int> v(a,a+5); //将数组a的内容放入v
vector<vector<int> > v(3); //二维数组
vector<int> v5(v2); //用v2初始化v5
vector<int> v4(v2.begin(), v2.end());
常用函数
| 函数 | |
|---|---|
| begin() | 返回指向容器中第一个元素的迭代器 |
| end() | 返回指向容器中最后一个元素后面的位置的迭代器 |
| rbegin() | 返回指向容器中最后一个元素的反向迭代器 |
| rend() | 返回指向容器中第一个元素前面的位置的反向迭代器 |
| clear() | 从容器中删除所有元素 |
| front() | 返回当前vector起始元素的引用 |
| back() | 返回当前vector结尾元素的引用 |
| size() | 返回元素个数 |
| empty() | 判断vector是否为空 |
| push_back(val) | 添加值为val的元素到当前vector末尾 |
| pop_back() | 删除当前vector最末的一个元素 |
| swap(from) | 当前vector与from的元素 |
| at(i) | 按下标访问 |
运算符
Vectors能够使用标准运算符: ==, !=, <=, >=, <, 和 >。
两个vectors被认为是相等的,如果: 它们具有相同的容量 && 所有相同位置的元素相等。
vectors之间大小的比较是按照词典规则。
1
2
3
4
5
6
7
v1 == v2
v1 != v2
v1 <= v2
v1 >= v2
v1 < v2
v1 > v2
v[]
按下标访问
成员函数at()会做范围检查,如果超出范围,会抛出out_of_range异常,而下标运算符[]不做范围检查
1
2
3
4
for(i = 0; i < 5; i++){
cout << vec[i] << endl;
cout << vec.at(i) << endl;
}
赋值
assign()函数
void assign( input_iterator start, input_iterator end ); //将区间[start, end)的元素赋到当前vector
void assign( size_type num, const TYPE &val ); //赋num个值为val的元素到vector
删除
erase()函数
iterator erase( iterator loc ); // 删除指定位置loc的元素,返回值是指向删除的元素的下一位置的迭代器。
iterator erase( iterator start, iterator end ); // 删除区间[start, end)的所有元素,返回值是指向删除的最后一个元素的下一位置的迭代器。
1
2
v.erase(v.begin() + 2);
v.erase(v.begin() + 1, v.begin() + 3);
插入
insert()函数
iterator insert( iterator loc, const TYPE &val ); // 在指定位置loc前插入值为val的元素,返回指向这个元素的迭代器。
void insert( iterator loc, size_type num, const TYPE &val ); // 在指定位置loc前插入num个值为val的元素
void insert( iterator loc, input_iterator start, input_iterator end ); // 在指定位置loc前插入区间[start, end)的所有元素
1
2
v.insert(v.begin() + 2, 13);
v2.insert(v2.begin(), v.begin()+ 1, v.begin()+3);
遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
vector<int>::iterator q = vec.begin();
while( q != vec.end()) { //v<vec.end()也行 vector是随机访问迭代器可以用<比较
cout << *q << endl;
q++;
}
vector<int>::reverse_iterator r;
for(r=vec.rbegin();r!=vec.rend();r++){
cout<<*r<<endl;
}
for(int i=0;i<v3.size();i++){
v3[i].push_back(i);
}
for(int i=0;i<v3.size();i++){
for(int j=0;j<v3[i].size();j++){
v3[i][j].push_back(i);
}
}
deque
所有适用于vector的操作都适用于deque
由于是双向队列,增加两个函数:
| 函数 | 含义 |
|---|---|
| push_front(val) | 在双向队列的头部加入一个值为val的元素 |
| pop_front() | 删除双向队列头部的元素 |
list
双向链表,不支持随机存取,不支持下标访问。
对象初始化
同vector
1
list<int> li;
常用函数
跟vector基本相同
| 函数 | |
|---|---|
| begin() | 返回指向容器中第一个元素的迭代器 |
| end() | 返回指向容器中最后一个元素后面的位置的迭代器 |
| rbegin() | 返回指向容器中最后一个元素的反向迭代器 |
| rend() | 返回指向容器中第一个元素前面的位置的反向迭代器 |
| clear() | 从容器中删除所有元素 |
| front() | 返回当前list起始元素的引用 |
| back() | 返回当前list结尾元素的引用 |
| size() | 返回元素个数 |
| empty() | 判断list是否为空 |
| push_back(val) | 添加值为val的元素到当前list末尾 |
| pop_back() | 删除当前list最末的一个元素 |
| push_front(val) | 在双向队列的头部加入一个值为val的元素 |
| pop_front() | 删除双向队列头部的元素 |
| swap(from) | 当前list与from的元素 |
| assign() | 赋值,用法参数同vector |
| erase() | 删除,用法参数同vector |
| insert() | 插入,用法参数同vector |
merge()
void merge( list &lst );
void merge( list &lst, Comp compfunction );
把自己和lst链表连接在一起,产生一个整齐排列的组合链表。(会清空lst)
如果指定compfunction,则将指定函数作为比较的依据。
1
lst1.merge(lst2); //合并lst2到lst1,并清空lst2,只是list2接在list1后边,顺序不动
remove()
void remove( const TYPE &val ); // 删除链表中所有值为val的元素
remove_if()
void remove_if( UnPred pr ); // 以一元谓词pr为判断元素的依据,遍历整个链表。如果pr返回true则删除该元素
sort()
- void sort();
- void sort( Comp compfunction );
链表排序,默认是升序。如果指定compfunction的话,就采用指定函数来判定两个元素的大小。
splice()
-
void splice( iterator pos, list &lst );
// 把lst连接到pos的位置,清空lst(pos位置原本的元素放在lst之后)
-
void splice( iterator pos, list &lst, iterator del );
// 把lst中del所指元素到现链表的pos的位置,删除lst中del所指元素
-
void splice( iterator pos, list &lst, iterator start, iterator end );
// 把lst中[start,end)所指元素到现链表的pos的位置,删除lst中[start,end)所指元素
unique()
- void unique();
- void unique( BinPred pr );
删除链表中所有重复的元素。如果指定pr,则使用pr来判定是否删除。
reverse()
把list所有元素倒转。
遍历
list是双向迭代器不可以用<比较
1
2
3
4
5
6
7
8
9
10
list<int>::iterator q = li.begin();
while( q != li.end()) { //q<li.end()不行 list是双向迭代器不可以用<比较
cout << *q << endl;
q++;
}
list<int>::reverse_iterator r;
for(r=li.rbegin();r!=li.rend();r++){
cout<<*r<<endl;
}
函数对象
- 类重载()可以成为函数对象
- 函数对象类模板 #include
,包含greater,less,equal_to等多个函数对象模板类 - list.sort()可以传入自定义的比较规则,可以是函数,可以是函数对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
#include <functional>
class CMyAverage {
public:
double operator () ( int a1, int a2, int a3 ) {
//重载 () 运算符
return (double)(a1+a2+a3) / 3;
}
};
class MyLess {
public:
bool operator()( const int & c1, const int & c2 )
{
return (c1 % 10) < (c2 % 10);
}
};
bool MyCompare(int a1,int a2)
{
return ( (a1%10) >= (a2%10) );
}
template <class T, class Pred>
T MyMax( T * p, int n, Pred myless)
{
T tmpmax = p[0];
for( int i = 1;i < n;i ++ )
if(myless(tmpmax,p[i]))
tmpmax = p[i];
return tmpmax;
};
template <class T>
void PrintInterval(T first, T last) //输出区间[first,last)中的元素
{
for( ; first != last; ++ first)
cout << * first << " ";
cout << endl;
}
int main()
{
CMyAverage average;
cout << average(3,2,3) << endl; //函数对象,用起来看上去像函数调用
cout << average.operator()(3,2,3) << endl;//和上一句是等价的 operator()是一个成员函数
//greater,less,equal_to 函数对象类模板 #include <functional>
int a[5] = {5,21,14,2,3};
list<int> lst(a,a+5);
lst.sort(MyLess()); //MyLess()是MyLess类的对象,个位数从小到大
PrintInterval(lst.begin(),lst.end());
lst.sort(greater<int>()); //greater<int>()是个对象,降序排序
PrintInterval(lst.begin(),lst.end());
lst.sort(MyCompare); //普通的函数MyCompare,个位数从大到小
PrintInterval(lst.begin(),lst.end());
int b[] = {35,7,13,19,12};
cout << MyMax(b,5,MyLess()) << endl; //函数对象 MyLess()
cout << MyMax(b,5,greater<int>()) << endl; //函数对象 greater<int>()
cout << MyMax(b,5,MyCompare) << endl; //普通的函数MyCompare
return 0;
}
set/multiset
- set即集合。set中不允许相同元素,multiset中允许存在相同的元素。
- 通常以平衡二叉树方式实现,插入和检索的时间都是 O(log(N))
对象初始化
- 默认使用<比较不同元素,使用自定义的类做set的元素,需要重载<。实际上是less<>函数对象。
- 也可以自定义比较方式,例如使用函数对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class A {
private:
int n;
public:
A(int n_ ) { n = n_; }
friend bool operator< ( const A & a1, const A & a2 ) { return a1.n < a2.n; }
friend ostream & operator<< ( ostream & o, const A & a2 ) { o << a2.n; return o; }
friend class MyLess;
};
class MyLess {
public:
bool operator()( const A & a1, const A & a2) //重载了() MyLess()是一个函数对象
{
return ( a1.n % 10 ) < (a2.n % 10);
}
};
multiset<A> m1; // 用"<"比较大小----A类需要重载<
// 相当于multiset<A, less<A>> m1;
multiset<A,MyLess> m2; // 用函数对象MyLess::operator()比较大小
int b[5] = {3,4,6,1,2};
set<int> st(b,b+5);
常用函数
| 函数 | |
|---|---|
| begin() | 返回指向容器中第一个元素的迭代器 |
| end() | 返回指向容器中最后一个元素后面的位置的迭代器 |
| rbegin() | 返回指向容器中最后一个元素的反向迭代器 |
| rend() | 返回指向容器中第一个元素前面的位置的反向迭代器 |
| clear() | 从容器中删除所有元素 |
| size() | 返回元素个数 |
| empty() | 判断set是否为空 |
| swap(from) | 当前set与from的元素 |
count()
size_type count( const key_type &key );
返回当前集合中出现的某个值的元素的数目
find()
iterator find( const key_type &key );
在当前集合中查找等于key值的元素,并返回指向该元素的迭代器;
如果没有找到,返回指向集合最后一个元素的迭代器。
1
2
3
4
5
multiset<A>::iterator pp = m1.find(19);
if( pp != m1.end() ) { // 条件为真说明找到
cout << "found" << endl;
cout << *pp << endl;
}
insert()
-
iterator insert( iterator i, const TYPE &val ); // 在迭代器i前插入val
-
void insert( input_iterator start, input_iterator end ); // 将迭代器[start,end)内的元素插入到集合中
-
pair<iterator, bool> insert( const TYPE &val ); // 在当前集合中插入val元素,并返回指向该元素的迭代器和一个布尔值来说明val是否成功的被插入了。
1
2
3
4
5
6
7
8
9
10
11
12
int b[5] = {3,4,6,1,2};
set<int> st(b,b+5);
pair<set<int>::iterator,bool> result; // 返回一个迭代器,一个bool
result = st.insert(5);
if(result.second){
cout<< *result.first <<" inserted"<<endl; // *(result.first) .比*优先级高
}
else{
cout<< *result.first <<" already exists"<<endl;
}
erase()
-
void erase( iterator i ); // 删除i
-
void erase( iterator start, iterator end ); // 删除[start,end)
-
size_type erase( const key_type &key ); // 删除等于key值的所有元素(返回被删除的元素的个数)
迭代器
-
iterator lower_bound( const key_type &key );
返回一个指向大于或者等于key值的第一个元素的迭代器。
-
iterator upper_bound( const key_type &key );
在当前集合中返回一个指向大于Key值的元素的迭代器。
-
pair equal_range( const key_type &key );
返回集合中与给定值相等的上下限的两个迭代器。相当于[ lower_bound, upper_bound )
key_comp()
key_compare key_comp();
返回一个用于元素间值比较的函数对象。
value_comp()
value_compare value_comp();
返回一个用于比较元素间的值的函数对象。
map/multimap
- map中存放的元素是pair模版类的对象,map根据first值对元素进行从小到大排序,并可快速地根据first来检索元素。
- map同multimap的不同在于是否允许相同first值的元素。
- map可以使用[key]索引,multimap不可以。(不是下标,是key)
- 内部数据结构为红黑树,插入和检索的时间都是 O(log(N))
对象初始化
- 默认使用<比较不同元素,使用自定义的类做map的元素,需要重载<。实际上是less<>函数对象。
- 也可以自定义比较方式,例如使用函数对象
1
2
map<int,double> pairs;
multimap<int,double,less<int> > pairs;
常用函数
| 函数 | |
|---|---|
| begin() | 返回指向容器中第一个元素的迭代器 |
| end() | 返回指向容器中最后一个元素后面的位置的迭代器 |
| rbegin() | 返回指向容器中最后一个元素的反向迭代器 |
| rend() | 返回指向容器中第一个元素前面的位置的反向迭代器 |
| clear() | 从容器中删除所有元素 |
| size() | 返回元素个数 |
| empty() | 判断set是否为空 |
| swap(from) | 当前set与from的元素 |
count()
size_type count( const key_type &key );
返回map中键值等于key的元素的个数
find()
iterator find( const key_type &key );
在当前集合中查找键值为key的元素,并返回指向该元素的迭代器;
如果没有找到,返回指向map最后一个元素的迭代器。
1
2
3
4
5
6
7
8
9
10
multimap<int,double,less<int> >::iterator pp = pairs.find(19);
if( pp != pairs.end() ) { //条件为真说明找到
cout << "found" << endl;
cout << pp->first << endl;
cout << pp->second << endl;
cout << (*pp).first << endl;
cout << (*pp).second << endl;
}
else
cout << "no found" << endl;
insert()
-
iterator insert( iterator pos, const pair<KEY_TYPE,VALUE_TYPE> &val ); // 插入val到pos的后面,然后返回一个指向这个元素的迭代器。
-
void insert( input_iterator start, input_iterator end ); // 将迭代器[start,end)内的元素插入到map中
-
pair<iterator, bool> insert( const pair<KEY_TYPE,VALUE_TYPE> &val ); // 在当前map中插入val元素,并返回指向该元素的迭代器和一个布尔值来说明val是否成功的被插入了。
可以使用value_type或者make_pair制造pair
multimap插入不会返回pair,因为总是会成功
1
2
3
4
5
6
7
typedef multimap<int,double,less<int> > mmid;
mmid pairs;
pairs.insert(mmid::value_type(15,2.7));
map<int,double,less<int> > pairs2;
cout << pairs2.insert(make_pair(15,9.7)).first->second << endl; // 9.7 .first返回迭代器
cout << pairs2.insert(make_pair(15,1.2)).second << endl; // 0 因为key重复 插入失败
erase()
-
void erase( iterator i ); // 删除i
-
void erase( iterator start, iterator end ); // 删除[start,end)
-
size_type erase( const key_type &key ); // 删除等于key值的所有元素
索引
map可以用[]使用key值进行索引,multimap不行
1
2
3
map<int,double,less<int> > pairs2;
int n = pairs2[40]; // 如果没有关键字为40的元素,则插入一个
pairs2[15] = 6.28; // 把关键字为15的元素值改成6.28
迭代器
-
iterator lower_bound( const key_type &key );
返回一个指向键值大于或者等于key值的第一个元素的迭代器。
-
iterator upper_bound( const key_type &key );
在当前map中返回一个指向键值大于Key值的元素的迭代器。
-
pair equal_range( const key_type &key );
返回两个迭代器:一个指向第一个键值为key的元素,另一个指向最后一个键值为key的元素。
key_comp()
key_compare key_comp();
返回一个用于元素间值比较的函数对象。
value_comp()
value_compare value_comp();
返回一个用于比较元素间的值的函数对象。
遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 重载了对pair的输出
template <class Key,class Value>
ostream & operator <<( ostream & o, const pair<Key,Value> & p)
{
o << "(" << p.first << "," << p.second << ")";
return o;
}
multimap<int,double,less<int> >::const_iterator i;
for( i = pairs.begin();i != pairs.end() ;i++ ){
// 迭代器用->
cout << "(" << i->first << "," << i->second << ")" << ",";
// pair用.
cout << "(" << (*i).first << "," << (*i).second << ")" << ",";
// 因为重载了pair<>的输出函数
cout<< *i << ",";
}
stack
- 可用 vector, list, deque来实现。缺省情况下,用deque实现。
- 用 vector和deque实现,比用list实现性能好。
- template<class T, class Cont = deque
>, 示例: `stack<int, deque > s;`
| 函数 | 含义 |
|---|---|
| empty() | 堆栈为空则返回真 |
| push() | 在栈顶增加元素,返回void类型 |
| pop() | 移除栈顶元素,返回void类型 |
| top() | 返回对栈顶元素的引用 |
| size() | 返回栈中元素数目 |
queue
- 可以用 list和deque实现。缺省情况下用deque实现。
- template<class T, class Cont = deque
>, 示例: `queue<string, vector > s;` - push发生在队尾;pop, top发生在队头。先进先出。
| 函数 | 含义 |
|---|---|
| empty() | 队列为空则返回真 |
| push() | 往队列中加入一个元素,返回void类型 |
| pop() | 删除队列的一个元素,返回void类型 |
| front() | 返回队列第一个元素的引用 |
| back() | 返回队列最后一个元素的引用 |
| size() | 返回队列中元素数目 |
priority_queue
- template <class T, class Container = vector
, class Compare = less > - 可以用vector和deque实现。缺省情况下用vector实现。
- 默认的元素比较器是less
,可以自己指定函数对象做比较器。
对象初始化
- 默认使用<比较不同元素,使用自定义的类做优先队列t的元素,需要重载<。实际上是less<>函数对象。
- 也可以自定义比较方式,例如使用函数对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class ox{
public:
int begin;
int end;
int num;
bool operator< (const ox & b) const { //const函数
return begin < b.begin; //优先队列begin大的在前
}
ox(int i, int j):begin(i),end(j),num(0) {}
ox() {}
};
class M {
public:
bool operator() (const ox & a, const ox & b) {
return a.begin > b.begin; //优先队列begin小的在前
}
};
ostream& operator << (ostream& o, const ox & x) {
o << x.begin << " " << x.end;
}
priority_queue<ox, vector<ox>, M > que; //法1.传入函数对象 重载()
priority_queue<ox> que2; //法2.类本身重载<
priority_queue<double> pq1;
priority_queue<double, vector<double>, greater<double> > pq2; //改用greater<>比较器
常用函数
| 函数 | 含义 |
|---|---|
| empty() | 队列为空则返回真 |
| push() | 往队列中加入一个元素,返回void类型,O(logn) |
| pop() | 删除队列的最高优先级的元素,返回void类型,O(logn) |
| top() | 返回队列的最高优先级的元素的引用,O(1) |
| size() | 返回队列中元素数目 |
bitset
算法
大多重载的算法都是有两个版本的
- 一个是用“==”判断元素是否相等,或用“<”来比较大小;
- 另一个多出来一个类型参数“Pred”,以及函数形参“Pred op”,该版本通过表达式“op(x,y)”的返回值是ture还是false,来判断x是否“等于”y,或者x是否“小于”y。
iterate min_element(iterate first,iterate last); iterate min_element(iterate first,iterate last, Pred op);
不变序列算法
此类算法不会修改算法所作用的容器或对象,适用于所有容器。时间复杂度都是O(n)的。
| 函数 | 含义 |
|---|---|
| min | 求两个对象中较小的(可自定义比较器) |
| max | 求两个对象中较大的(可自定义比较器) |
| min_element(FwdIt first, FwdIt last); | 返回[first,last) 中最小元素的迭代器,以 “< ”作比较器。 |
| max_element(FwdIt first, FwdIt last); | 返回[first,last) 中最大元素(它不小于任何其他元素,但不见得其他不同元素都小于它)的迭代器,以 “< ”作比较器。 |
| for_each(InIt first, InIt last, Fun f) | 对[first,last)中的每个元素 e ,执行 f(e) , 要求 f(e)不能改变e。 |
| count(InIt first, InIt last, const T& val); | 计算[first,last) 中等于val的元素个数 |
| count_if(InIt first, InIt last, Pred pr); | 计算[first,last) 中符合pr(e) == true 的元素 e的个数 |
| find(InIt first, InIt last, const T& val); | 返回区间 [first,last) 中的迭代器 i ,使得 * i == val |
| find_if(InIt first, InIt last, Pred pr); | 返回区间 [first,last) 中的迭代器 i, 使得 pr(*i) == true |
| find_end | 在区间中查找另一个区间最后一次出现的位置(可自定义比较器) |
| find_first_of | 在区间中查找第一个出现在另一个区间中的元素 (可自定义比较器) |
| adjacent_find | 在区间中寻找第一次出现连续两个相等元素的位置(可自定义比较器) |
| search | 在区间中查找另一个区间第一次出现的位置(可自定义比较器) |
| search_n | 在区间中查找第一次出现等于某值的连续n个元素(可自定义比较器) |
| equal | 判断两区间是否相等(可自定义比较器) |
| mismatch | 逐个比较两个区间的元素,返回第一次发生不相等的两个元素的位置( 可自定义比较器) |
| lexicographical_compare | 按字典序比较两个区间的大小(可自定义比较器) |
变值算法
会修改源区间或目标区间元素的值。值被修改的那个区间,不可以是属于关联容器的。
| 函数 | 含义 |
|---|---|
| for_each | 对区间中的每个元素都做某种操作 |
| copy | 复制一个区间到别处 |
| copy_backward | 复制一个区间到别处,但目标区间是从后往前被修改的 |
| transform | 将一个区间的元素变形后拷贝到另一个区间 |
| swap_ranges | 交换两个区间内容 |
| fill | 用某个值填充区间 |
| fill_n | 用某个值替换区间中的n个元素 |
| generate | 用某个操作的结果填充区间 |
| generate_n | 用某个操作的结果替换区间中的n个元素 |
| replace | 将区间中的某个值替换为另一个值 |
| replace_if | 将区间中符合某种条件的值替换成另一个值 |
| replace_copy | 将一个区间拷贝到另一个区间,拷贝时某个值要换成新值拷过去 |
| replace_copy_if | 将一个区间拷贝到另一个区间,拷贝时符合某条件的值要换成新值拷过去 |
删除算法
删除算法会删除一个容器里的某些元素。
这里所说的 “删除”,并不会使容器里的元素减少,其工作过程是:将所有应该被删除的元素看做空位子,然后用留下的元素从后往前移,依次去填空位子。元素往前移后,它原来的位置也就算是空位子,也应由后面的留下的元素来填上。最后,没有被填上的空位子,维持其原来的值不变。
删除算法不应作用于关联容器。
| 函数 | 含义 |
|---|---|
| remove | 删除区间中等于某个值的元素 |
| remove_if | 删除区间中满足某种条件的元素 |
| remove_copy | 拷贝区间到另一个区间。等于某个值的元素不拷贝 |
| remove_copy_if | 拷贝区间到另一个区间。符合某种条件的元素不拷贝 |
| unique | 删除区间中连续相等的元素,只留下一个(可自定义比较器) |
| unique_copy | 拷贝区间到另一个区间。连续相等的元素,只拷贝第一个到目标区间 (可自定义比较器) |
template<class FwdIt> FwdIt unique(FwdIt first, FwdIt last);
用 == 比较是否等
template<class FwdIt, class Pred> FwdIt unique(FwdIt first, FwdIt last, Pred pr);
用 pr 比较是否等
对[first,last) 这个序列中连续相等的元素,只留下第一个。
返回值是迭代器,指向元素删除后的区间的最后一个元素的后边。
变序算法
- 变序算法改变容器中元素的顺序,但是不改变元素的值。
- 变序算法不适用于关联容器。
- 此类算法复杂度都是O(n)的。
| 函数 | 含义 |
|---|---|
| reverse | 颠倒区间的前后次序 |
| reverse_copy | 把一个区间颠倒后的结果拷贝到另一个区间,源区间不变 |
| rotate | 将区间进行循环左移 |
| rotate_copy | 将区间以首尾相接的形式进行旋转后的结果拷贝到另一个区间,源区间不变 |
| next_permutation | 将区间改为下一个排列(可自定义比较器),返回bool |
| prev_permutation | 将区间改为上一个排列(可自定义比较器) |
| random_shuffle | 随机打乱区间内元素的顺序 |
| partition | 把区间内满足某个条件的元素移到前面,不满足该条件的移到后面 |
| stable_patition | 把区间内满足某个条件的元素移到前面,不满足该条件的移到后面。而且对这两部分元素,分别保持它们原来的先后次序不变 |
random_shuffle :
template<class RanIt> void random_shuffle(RanIt first, RanIt last);
随机打乱[first,last) 中的元素,适用于能随机访问的容器
用之前要初始化伪随机数种子:
#include
srand(unsigned(time(NULL)));
1
2
3
4
string str = "231";
while (next_permutation(str.begin(), str.end())){
cout << str << endl;
}
排序算法
排序算法比前面的变序算法复杂度更高,一般是O(n×log(n))。
排序算法需要随机访问迭代器的支持,因而不适用于关联容器和list。
| 函数 | 含义 |
|---|---|
| sort | 将区间从小到大排序(可自定义比较器) |
| stable_sort | 将区间从小到大排序,并保持相等元素间的相对次序(可自定义比较器) |
| partial_sort | 对区间部分排序,直到最小的n个元素就位(可自定义比较器) |
| partial_sort_copy | 将区间前n个元素的排序结果拷贝到别处。源区间不变(可自定义比较器) |
| nth_element | 对区间部分排序,使得第n小的元素(n从0开始算)就位,而且比它小的都在它前面,比它大的都在它后面(可自定义比较器) |
| make_heap | 使区间成为一个“堆”(可自定义比较器) |
| push_heap | 将元素加入一个是“堆”区间(可自定义比较器) |
| pop_heap | 从 “堆”区间删除堆顶元素(可自定义比较器) |
| sort_heap | 将一个“堆”区间进行排序,排序结束后,该区间就是普通的有序区间,不再是 “堆”了(可自定义比较器)。 |
sort:
template<class RanIt> void sort(RanIt first, RanIt last);
按升序排序。判断x是否应比y靠前,就看 x < y 是否为true
template<class RanIt, class Pred> void sort(RanIt first, RanIt last, Pred pr);
按升序排序。判断x是否应比y靠前,就看 pr(x,y) 是否为true
排序算法要求随机存取迭代器的支持,所以list 不能使用排序算法,要使用list::sort。
make_heap:
template<class RanIt> void make_heap(RanIt first, RanIt last);
将区间 [first,last) 做成一个堆。用 < 作比较器
template<class RanIt, class Pred> void make_heap(RanIt first, RanIt last, Pred pr);
将区间 [first,last) 做成一个堆。用 pr 作比较器
push_heap:
template<class RanIt> void push_heap(RanIt first, RanIt last);
template<class RanIt, class Pred> void push_heap(RanIt first, RanIt last, Pred pr);
在[first,last-1)已经是堆的情况下,该算法能将[first,last)变成堆,时间复杂度O(log(n))。
往已经是堆的容器中添加元素,可以在每次 push_back 一个元素后,再调用 push_heap算法。
pop_heap:
取出堆中最大的元素,复杂度 O(log(n))
template<class RanIt> void pop_heap(RanIt first, RanIt last);
template<class RanIt, class Pred> void pop_heap(RanIt first, RanIt last, Pred pr);
原[first,last)是个堆,将堆中的最大元素,即 * first ,移到 last –1 位置,原 * (last –1 )被移到前面某个位置,并且移动后[first,last –1)仍然是个堆。
有序区间算法
有序区间算法要求所操作的区间是已经从小到大排好序的,而且需要随机访问迭代器的支持。
所以有序区间算法不能用于关联容器和list。
| 函数 | 含义 |
|---|---|
| binary_search | 判断区间中是否包含某个元素。折半查找。 |
| includes | 判断是否一个区间中的每个元素,都在另一个区间中。 |
| lower_bound | 查找最后一个不小于某值的元素的位置。 |
| upper_bound | 查找第一个大于某值的元素的位置。 |
| equal_range | 同时获取lower_bound和upper_bound。 |
| merge | 合并两个有序区间到第三个区间。 |
| set_union | 将两个有序区间的并拷贝到第三个区间。 |
| set_intersection | 将两个有序区间的交拷贝到第三个区间。 |
| set_difference | 将两个有序区间的差拷贝到第三个区间。 |
| set_symmetric_difference | 将两个有序区间的对称差拷贝到第三个区间。 |
| inplace_merge | 将两个连续的有序区间原地合并为一个有序区间。 |
演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
class MyLess {
public:
bool operator()( int n1,int n2) {
return (n1 % 10) < ( n2 % 10);
}
};
void printVec(vector<int> nums)
{
for (int i = 0; i < nums.size(); ++i)
cout << nums[i] << " ";
cout << endl;
}
bool Greater10(int n)
{
return n > 10;
}
int main()
{
// next_permutation
string str = "231";
char szStr[] = "324";
while (next_permutation(str.begin(), str.end()))
{
cout << str << endl;
}
while (next_permutation(szStr,szStr + 3))
{
cout << szStr << endl;
}
sort(str.begin(),str.end());
while (next_permutation(str.begin(), str.end()))
{
cout << str << endl;
}
int aa[] = { 1,2,3 };
list<int> ls(aa , aa + 3);
while( next_permutation(ls.begin(),ls.end()))
{
list<int>::iterator i;
for( i = ls.begin();i != ls.end(); ++i)
cout << * i << " ";
cout << endl;
}
// sort 快速排序
int a[] = { 14,2,9,111,78 };
sort(a,a + 5,MyLess());
sort(a,a+5,greater<int>());
// make_heap
int nums_temp[] = {8, 3, 4, 8, 9, 2, 3, 4, 10};
vector<int> nums(nums_temp, nums_temp + 9);
cout << "make_heap之前: ";
printVec(nums);
cout << "(默认(less))make_heap: ";
make_heap(nums.begin(), nums.end());
printVec(nums);
cout << "(less)make_heap: ";
make_heap(nums.begin(), nums.end(), less<int> ());
printVec(nums);
cout << "(greater)make_heap: ";
make_heap(nums.begin(), nums.end(), greater<int> ());
printVec(nums);
cout << "此时,nums为小顶堆 greater" << endl;
cout << "push_back(3)" << endl;
nums.push_back(3);
cout << "默认(less)push_heap 此时push_heap失败: ";
push_heap(nums.begin(), nums.end());
printVec(nums);
cout << "push_heap为greater 和make_heap一致,此时push_heap成功: ";
push_heap(nums.begin(), nums.end(), greater<int>());
printVec(nums);
cout << "(greater,不然会失败)pop_heap: ";
pop_heap(nums.begin(), nums.end(),greater<int>());
printVec(nums);
cout << "pop_back(): ";
nums.pop_back();
printVec(nums);
// binary_search 要求原序列有序
// find,find_if
const int SIZE = 10;
int a1[] = { 2,8,1,50,3,100,8,9,10,2 };
vector<int> v(a1,a1+SIZE);
vector<int>::iterator location;
location = find(v.begin(),v.end(),10);
if( location != v.end()) {
cout << "1) " << location - v.begin()<< endl ;
}
location = find_if( v.begin(),v.end(),Greater10);
if( location != v.end()){
cout << "2) " << location - v.begin()<< endl ;
}
sort(v.begin(),v.end());
for (vector<int>::iterator i = v.begin();i!=v.end();i++) {
cout << *i << " ";
}
cout << endl;
if( binary_search(v.begin(),v.end(),9)) {
cout << "3) " << "9 found"<< endl ;
}
return 0;
}
C++11
统一的初始化方法
允许使用{}进行各类对象包括容器对象的初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
int arr[3]{1, 2, 3};
// int arr[3] = {1, 2, 3}; C++98 / C
vector<int> iv{1, 2, 3};
map<int, string> mp{ {1, "a"}, {2, "b"}};
string str{"Hello World"};
set<int> ss{1,2,3};
int * p = new int[20]{1,2,3};
struct A {
int i,j;
A(int m,int n):i(m),j(n) {
printA();
}
void printA() {
cout << i << " " << j << endl;
}
};
A func(int m,int n) {
return {m,n};
}
vector<int> func(int a,int b,int c) {
return {a,b,c};
}
int main() {
A * pa = new A {0,5};
A a1{1,5};
A a2(2,5);
A a3 = {3,5};
A a4 = func(4,5);
vector<int> ve = func(1,2,3);
cout << ve[0] << " " << ve[1] << " " << ve[2] << endl;
}
成员变量默认初始值
1
2
3
4
5
6
7
8
class B {
public:
int m = 10;
int n;
}
B b;
cout << b.m << endl;
auto关键字
- 用于定义变量,编译器可以自动判断变量的类型,定义的变量必须初始化
- 定义在一个auto序列的变量必须始终推导成同一类型
- 函数和模板的参数不能被声明为auto
- auto是一个占位符,不能用于类型转换或其他一些操作,如sizeof和typeid
- auto可以做函数返回值的占位符,需要使用
-> decltype指明类型 - auto可以用于引用类型,可以自动判断是不是const引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class A {
public:
int a;
A(int a_): a(a_) {}
};
A operator + ( int n,const A & a)
{
return a.a+n;
}
template <class T1, class T2>
auto add(T1 x, T2 y) -> decltype(x + y) {
return x+y;
}
int main() {
auto i = 100; // int
auto p = new A(6); // p是A*
auto l = 33333LL; // long long
// auto x1 = 5, x2 = 5.0, x3='r'; 错误
map<string,int,greater<string> > mp;
for (auto i = mp.begin(); i != mp.end(); ++i) {} // 迭代器
auto d = add(100,1.5); // d是double
cout << d << endl;
auto k = add(100,A(5)); // d是A
cout << k.a << endl;
const int ii = 99;
auto jj = ii; // jj is int
jj = 100; // 修改jj与ii无关
auto& kk = ii; // kk is const int&
//kk = 100; // 常引用不可以用来修改原值
int ll = 99;
auto& qq = ll; // qq is int&
qq = 100; // 普通引用可以用来修改原值
cout << qq << " " << ll << endl;
}
decltype关键字
求指定表达式的类型。在此过程中,编译器分析表达式并得到它的类型,却不实际计算表达式的值。
1
2
3
4
5
6
7
8
9
int i;
double t;
struct A { double x;};
const A* a = new A();
decltype(a) x1; // x1是A*
decltype(i) x2; // x2是int
decltype(a->x) x3; // x3是double
decltype(a->x) x4 = t; // x4是double &
基于范围的for循环
使用for(:)循环,可以结合auto关键字,可以使用引用类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
int main() {
int arr[]{1,2,3,4,5};
for (int & e: arr) {
e *= 10;
}
for (int e: arr) {
cout << e << ",";
}
cout << endl;
vector<int> ve(arr, arr+5);
for (auto & it: ve) {
it *= 10;
}
for (auto it: ve) {
cout << it << ",";
}
cout << endl;
map<int,int> mp{ {1,2},{2,3},{3,4}};
for (auto it: mp) {
cout << it.first << "," << it.second << endl;
}
set<int> ss{1,2,3};
for (auto it: ss) {
cout << it << endl;
}
}
unordered_map
#include
-
内部数据结构为哈希表,可以实现快速查找,其元素的排列顺序是无序的
-
哈希表插入和查询的时间复杂度几乎是常数O(1)
-
哈希表的建立比较耗费时间
-
遍历顺序与创建该容器时输入的顺序不一定相同,遍历是按照哈希表从前往后依次遍历的
-
使用方法同map,也可以使用[]索引
1
2
3
4
5
6
7
8
9
10
11
12
int main() {
unordered_map<int, string> myMap={ { 5, "aaa" },{ 6, "bbb" }};
myMap[2] = "ccc"; //使用[]
myMap.insert(make_pair(3, "ddd"));
auto iter = myMap.begin();
while (iter!= myMap.end())
{
cout << iter->first << "," << iter->second << endl;
++iter;
}
}
正则表达式
#include
Lambda表达式
多线程
#include
强制类型转换
异常处理
try、catch
参考
https://www.icourse163.org/course/PKU-1002029030
转载请标明如下内容:
本文作者:姜佳伟
本文链接:https://aptx1231.github.io/2020/12/01/C++%E6%95%B4%E7%90%86/
Github:aptx1231

