Python
基础语法
list
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
a = ['Michael', 'Bob', 'Tracy'] # 直接写[]
[x for x in range(1, 11)] # 推导表达式
[x for x in range(1, 11) if x % 2 == 0] # 推导表达式
# 赋值
a[1] = 'Sarah'
# 追加元素到末尾
a.append('Adam')
# 把元素插入到指定的位置
a.insert(1, 'Jack')
# 删除list末尾的元素
a.pop()
# 指定删除的位置
a.pop(2)
# 按照下标删除
del a[1]
# 按值删除 只删除第一次出现的
a.remove("A")
# 排序后 不可恢复
a.sort()
a.sort(reverse=True)
# 临时排序 a本身不变
sorted(a)
sorted(a, reverse=True)
# 翻转a
a.reverse()
# 列表内容复制 不是同一个
ss = strs[:]
dict
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} # 直接{}写dict
d = {x: x**2 for x in (2, 4, 6)} # 推导表达式
d = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)]) # 从键值对元组列表中构建
d = dict(sape=4139, guido=4127, jack=4098) # 使用关键字参数指定键值对
# 一个key只能对应一个value,多次对一个key放入value,后面的值会把前面的值冲掉
d['Jack'] = 90
# 如果key不存在,dict就会报错
d['Thomas'] # 报错
# 判断是不是key
'Thomas' in d # True or False
d.get('Thomas') # 如果key不存在,可以返回None
d.get('Thomas', -1) # 如果key不存在,可以返回-1
# 删除一个key, 对应的value也会从dict中删除
d.pop('Bob')
# dict的key必须是不可变对象 不能用list作为key
# 迭代dict
for k, v in d.items():
print(k, '=', v)
for k in d.keys():
print(k + " " + d[k])
for k in d: # 遍历字典默认遍历key 所以这个跟上一行结果一样
print(k + " " + d[k])
for v in d.values():
print(v)
f = {
'a': {
'A': 'AA',
'AA': 'AAA', # 字典中嵌套字典
},
'b': {
'B': 'BB',
'BB': 'BBB',
},
}
set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
s = {'apple', 'orange', 'apple', 'pear'} # 直接{}写set
s = set([1, 2, 3]) # set()
s = {x for x in 'abracada' if x not in 'abc'} # 推导表达式
a = {} # 空字典
b = set() # 空集合
# 添加元素到set中,可以重复添加,但不会有效果
s.add(4)
# 删除元素, 如果不存在会报错
s.remove(4)
# 交集
s1 & s2
# 并集
s1 | s2
# 差集 在s1中但不在s2中
s1 - s2
# 对称差 在s1或s2中的,但不同时在s1和s2中
s1 ^ s2
可变参数
1
2
3
4
5
6
7
8
9
10
11
12
def calc(*numbers): # *numbers 可变参数
sum = 0
for n in numbers:
sum = sum + n * n
return sum
# 函数调用
calc(1, 2, 3, 4)
calc()
nums = [1, 2, 3]
calc(nums[0], nums[1], nums[2]) # 比较麻烦
calc(*nums) # *nums表示把nums这个list的所有元素作为可变参数传进去
关键字参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 函数调用
person('Michael', 30)
# name: Michael age: 30 other: {}
person('Bob', 35, city='Beijing')
# name: Bob age: 35 other: {'city': 'Beijing'}
person('Adam', 45, gender='M', job='Engineer')
# name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
extra = {'city': 'Beijing', 'job': 'Engineer'}
person('Jack', 24, city=extra['city'], job=extra['job']) # 比较麻烦
person('Jack', 24, **extra)
# **extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数
# 对kw的改动不会影响到函数外的extra
enumerate
1
2
3
# 把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身
for index, value in enumerate(['A', 'B', 'C']):
print(index, value)
isinstance
1
2
3
4
5
isinstance('a', str)
isinstance(123, int)
isinstance(b'a', bytes)
isinstance([1, 2, 3], (list, tuple))
isinstance((1, 2, 3), (list, tuple))
zip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象
# 使用 list() 转换来输出列表
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
# 利用 * 号操作符,可以将元组解压为列表
a = [1,2,3]
b = [4,5,6]
list(zip(a,b))
# [(1, 4), (2, 5), (3, 6)]
# zip(* ) 可理解为解压,返回二维矩阵式
a1, a2 = zip(*zip(a,b))
# [1, 2, 3], [4, 5, 6]
a = [[1,2,3], [4,5]]
b = [[11,12,13], [14,15]]
list(zip(a,b))
# [([1, 2, 3], [11, 12, 13]), ([4, 5], [14, 15])]
a = [1, 2, 3]
b = [[11,12,13], [14,15]]
list(zip(a,b))
# [(1, [11, 12, 13]), (2, [14, 15])]
列表生成式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
[x for x in range(1, 11)]
# for后面的if是过滤条件,不能带else
[x for x in range(1, 11) if x % 2 == 0]
# [2, 4, 6, 8, 10]
# for前面的if ... else是表达式
[x if x % 2 == 0 else -x for x in range(1, 11)]
# [-1, 2, -3, 4, -5, 6, -7, 8, -9, 10]
[m + n for m in 'ABC' for n in 'XYZ']
# ['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
[k + '=' + v for k, v in d.items()]
[s.lower() for s in L]
matrix = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ]
[[row[i] for row in matrix] for i in range(4)]
# [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
生成器 generator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 简单生成器 把列表生成式的[]换成()
g = (x * x for x in range(10))
# 获得generator的下一个返回值,没有更多的元素时,抛出StopIteration的错误
next(g)
# yield生成器在每次调用next()时执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'hahaha'
for n in fib(6):
print(n)
# 输出6个数字
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e: # 迭代到最后会报异常 从函数的return返回
print('Generator return value:', e.value) # 输出hahaha
break
迭代器
1
2
3
# 凡是可作用于for循环的对象都是Iterable类型;
# 凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
# 集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象
函数式编程
map()
1
2
3
4
5
6
# 接收两个参数,一个是函数,一个是Iterable,
# 将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
list(r) # r是一个Iterator,需要转list
reduce()
1
2
3
4
5
6
# 把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数
# reduce把结果继续和序列的下一个元素做累积计算
# reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
def add(x, y):
return x * 10 + y
reduce(add, [1, 3, 5, 7, 9]) # =13579
filter()
1
2
3
4
5
6
# 接收一个函数和一个序列
# 把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])) # 结果: [1, 5, 9, 15]
# 返回的是一个Iterator,是一个惰性序列
sorted()
1
2
3
4
5
sorted([36, 5, -12, 9, -21]) # 从小到大排序
sorted([36, 5, -12, 9, -21], key=abs) # 按绝对值大小排序
sorted(['bob', 'about', 'Zoo', 'Credit']) # 按ascii码
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) # 忽略大小写的排序
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) # 反向排序
lambda表达式
1
2
3
4
f = lambda x: x * x
f(5) # =25
sums = lambda arg1, arg2: arg1 + arg2
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
错误处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# try如果执行出错,则后续代码不会继续执行,而是直接跳转至except语句块
# 执行完except后,如果有finally语句块,则执行finally语句块
# 即使try不出错,如果有finally语句块,也会执行finally语句块
# 可以有多个except来捕获不同类型的错误
# 可以在except语句块后面加一个else,当没有错误发生时,会自动执行else语句
try:
print('try...')
r = 10 / 0
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else:
print('no error!')
finally:
print('finally...')
print('END')
# 抛出错误 raise
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
# raise语句如果不带参数,就会把当前错误原样抛出。
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
# 在except中raise一个Error,还可以把一种类型的错误转化成另一种类型
try:
10 / 0
except ZeroDivisionError:
raise ValueError('input error!')
常用模块
os
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 查看当前目录的绝对路径
os.path.abspath('.')
# 把两个路径合成一个
os.path.join('/Users/michael', 'testdir')
# 拆分路径
os.path.split('/Users/michael/testdir/file.txt')
# ('/Users/michael/testdir', 'file.txt')
# 得到文件扩展名
os.path.splitext('/path/to/file.txt')
# ('/path/to/file', '.txt')
# 创建一个目录
os.mkdir('/Users/michael/testdir')
# 删掉一个目录
os.rmdir('/Users/michael/testdir')
# 对文件重命名
os.rename('test.txt', 'test.py')
# 删掉文件
os.remove('test.py')
# 列出当前目录下的所有目录
[x for x in os.listdir('.') if os.path.isdir(x)]
# 列出所有的.py文件
[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
random
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
1
2
3
4
5
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = "-";
seq = ("a", "b", "c"); # 字符串序列
print str.join( seq );
random.uniform(x, y) 方法将随机生成一个实数,它在 [x,y] 范围内。
1
2
import random
random.uniform(x, y)
random.sample
1
2
3
4
5
import random
y=list(range(1,10))
slice = random.sample(y, 5)
print (slice)
输出: [6, 3, 9, 4, 8]
解释:从list中随机获取5个元素,作为一个列表
注意:此random.sample,不是np.random.sample,算法使用不同
pickle
1
2
3
4
5
6
7
8
9
10
11
12
13
# dumps()把任意对象序列化成一个bytes
d = dict(name='Bob', age=20, score=88)
pickle.dumps(d)
# dump()直接把对象序列化后写入一个file-like Object
f = open('dump.txt', 'wb')
pickle.dump(d, f)
f.close()
# load()从一个file-like Object中直接反序列化出对象
f = open('dump.txt', 'rb')
d = pickle.load(f)
f.close()
json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# dumps()方法把Python对象变成一个JSON的字符串
d = dict(name='Bob', age=20, score=88)
json.dumps(d)
# '{"age": 20, "score": 88, "name": "Bob"}'
# loads()把JSON的字符串反序列化成Python对象
json_str = '{"age": 20, "score": 88, "name": "Bob"}'
json.loads(json_str)
# {'age': 20, 'score': 88, 'name': 'Bob'}
# dump()方法把Python对象的JSON写入一个file-like Object
# load()从file-like Object中读取字符串并反序列化
nums = [1, 2, 4, 6, 9]
with open('nums.json', 'w') as file:
json.dump(nums, file) # 存
with open('nums.json', 'r') as file:
nums = json.load(file) # 取
print(nums)
re
1
2
3
4
5
6
7
8
9
10
11
12
s = 'ABC\\-001' # Python的字符串
s = r'ABC\-001' # r前缀就不用考虑转义的问题
# match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None
m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
m.group(0) # 原始字符串 '010-12345'
m.group(1) # 第一个子串 '010'
m.group(2) # 第二个子串 '12345'
m.groups() # ('010', '12345')
# 先编译再匹配
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
re_telephone.match('010-12345').groups() # ('010', '12345')
tkinter
turtle
机器学习
numpy
1
import numpy as np
np.array
1
2
3
4
5
6
7
8
9
10
a = np.array([1, 2, 3])
a.ndim # 维度
a.shape # 尺度,对于矩阵,n行m列
a.size # 元素的个数,相当于.shape中n*m的值
a.dtype # 元素类型
a.itemsize # 每个元素的大小,以字节为单位
a = np.array([1, 2, 3, 4, 5], ndmin=2) # 设置最小维度=2
a = np.array([1, 2, 3], dtype=complex) # 设置数组元素的类型为负数
a = np.array((1, 2, 3))
np.asarray
1
# array和asarray都可以将结构数据转化为ndarray,但是主要区别就是当数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会
np.arrange
1
2
3
# 类似range()函数,返回ndarray类型,元素从0到n‐1
np.arange(10)
np.arange(1, 10, 2)
数组变型
1
2
3
4
5
6
a = np.ones((2, 3, 4), dtype=np.int32)
a.reshape((3, 8)) # 不改变数组元素,返回一个shape形状的数组,原数组不变
a.resize((3, 8)) # 与reshape()功能一致,但修改原数组
a.flatten() # 对数组进行降维为一维的,返回折叠后的数组,原数组不变 shape=(24,) ndim=1
a.astype(np.float) # 类型转换
a.tolist() # 转换成列表
特殊数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 根据shape生成一个全1数组,shape是元组类型
np.ones((2, 3))
# 根据shape生成一个全0数组,shape是元组类型
np.zeros((4, 5), dtype=np.int32)
# 创建一个正方的n*n单位矩阵,对角线为1,其余为0
np.eye(3)
# 根据shape生成一个数组,每个元素值都是value
np.full((10,), 2)
a = np.array([[1, 2, 3], [4, 5, 6]])
# a的形状的全1数组
np.ones_like(a)
# a的形状的全0数组
np.zeros_like(a)
# a的形状的全value数组
np.full_like(a, 10)
数组切片
1
2
3
4
5
6
7
8
9
10
11
12
a = np.array([1, 2, 3, 4, 5, 6])
a[2] # 索引
a[1:5:2] # 切片 1到5 间隔2
a = np.arange(24).reshape((2, 3, 4)) # ndim=3
a[1, 2, 3] # 索引 逗号分隔是各个维度
a[-1, -2, -3]
a[:, 1, -3] # :切片 起点:终点:间隔 不包括终点
a[:, :, 2:] # 2: 从2开始到最后
a[:, :, :2] # :2 从0到1 不包括2
a[:, :, 2:3] # 2:3 从2到2 不包括3
a[:, :, ::2] # ::2 整行 间隔为2
数组计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
a = np.arange(24).reshape((2, 3, 4)) # ndim=3 2*3*4
b = np.square(a)
np.sqrt(a)
np.square(a)
np.maximum(a, b)
a + b
a < b
np.sum(a)
np.mean(a, axis=0) # 3*4
np.mean(a, axis=1) # 2*4
np.mean(a, axis=2) # 2*3
np.average(a, axis=0, weights=[10, 5, 1])
np.std(a) # 标准差
np.var(a) # 方差
np.max(a)
数组存取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# np.savetxt 只能存1,2维
# np.loadtxt 默认取出float类型
a = np.arange(24).reshape((4, 6))
np.savetxt('ad.csv', a, fmt='%d', delimiter=',')
np.savetxt('af.csv', a, fmt='%.1f', delimiter=',')
b = np.loadtxt('ad.csv', delimiter=',')
b = np.loadtxt('ad.csv', dtype=np.int, delimiter=',')
# tofile() 存高纬的数组
# np.fromfile 取出来之后形状丢失
a = np.arange(24).reshape((2, 3, 4))
a.tofile('bd.txt', sep=',', format='%d') # sep:数据分割字符串,指定sep则写入文件不是二进制
b = np.fromfile('bd.txt', sep=',', dtype=np.int) # 形状丢失了
a.tofile('bd.bat', format='%d') # 不指定sep 写入的文件是二进制文件
b = np.fromfile('bd.bat', dtype=np.int) # 形状丢失了
# np.save 可以存高纬的数组
# np.load 保留形状
a = np.arange(24).reshape((2, 3, 4))
np.save('a.npy', a) # 形状保留了
b = np.load('a.npy')
np.linspace
1
2
3
4
5
# 根据起止数据等间距地填充数据,形成数组
a = np.linspace(1, 10, 4)
# array([ 1., 4., 7., 10.])
b = np.linspace(1, 10, 4, endpoint=False)
# array([1. , 3.25, 5.5 , 7.75])
np.concatenate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 按轴axis连接array组成一个新的array
a = np.array([[1, 2], [3, 4]]) # 2*2
b = np.array([[5, 6], [7, 8]]) # 2*2
np.concatenate((a,b),axis=0) # 4*2
#array([[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]])
np.concatenate((a,b),axis=1) # 2*4
#array([[1, 2, 5, 6],
# [3, 4, 7, 8]])
a = np.array([[1, 2], [3, 4]]) # 2*2
b = np.array([[5, 6]]) # 1*2
np.concatenate((a,b),axis=0) # 3*2
#array([[1, 2],
# [3, 4],
# [5, 6]])
np.concatenate((a,b.T),axis=1) # 2*3 b.T是2*1的
#array([[1, 2, 5],
# [3, 4, 6]])
np.random
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# .rand 创建随机数数组,浮点数,[0,1),均匀分布
np.random.rand(1, 10) # 二维
np.random.rand(10) # 一维
np.random.rand(2, 3, 4) # 三维
# .randn 创建随机数数组,标准正态分布
np.random.randn(2, 3, 4) # 三维
# .randint 生成size个整数,取值区间为[low, high),若没有输入参数high则取值区间为[0, low)
# randint(low, high=None, size=None, dtype='l')
np.random.randint(10, 100, (3, 4))
# 产生具有均匀分布的数组,low起始值,high结束值,size形状
np.random.uniform(0, 12, (3, 4))
# 产生具有正态分布的数组,loc均值,scale标准差,size形状
np.random.normal(0, 10, (2, 5))
# .random 产生[0.0, 1.0)之间的浮点数数组
numpy.random.random((10,2))
# 根据数组a的第1轴进行随排列,改变数组a
np.random.shuffle(a)
# .permutation 返回随机排列
np.random.permutation(10) # array([1, 7, 4, 3, 0, 9, 2, 5, 8, 6])
# .permutation 根据数组a的第1轴产生一个新的乱序数组,不改变数组a
np.random.permutation(a)
np.random.permutation([1, 4, 9, 12, 15])
# .choice 从[0, 5)中随机输出一个随机数
np.random.choice(5)
# .choice 在[0, 5)内输出五个数字并组成一维数组 形状(3,)
np.random.choice(5, 3)
# 从数组中抽取 replace=True表示可以取相同数字 replace=False表示不可以取相同数字,默认True
a = np.arange(24)
np.random.choice(a, (4, 3)) # 可以重复
np.random.choice(a, (4, 3), replace=True) # 可以重复
np.random.choice(a, (4, 3), replace=False) # 不可以重复
np.random.choice(a, (4, 3), replace=False, p=a/np.sum(a)) # p参数指定概率
np.nonzero
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 得到数组array中非零元素的位置(数组索引)的函数,返回tuple
a = np.array([[1, 0, 3], [0, 2, 0], [0, 0, 9]])
b = np.nonzero(a)
# b: (array([0, 0, 1, 2], dtype=int64), array([0, 2, 1, 2], dtype=int64))
# 上下对应对看
# [0, 0, 1, 2]
# [0, 2, 1, 2]
# (0,0) (0,2) (1,1) (2,2)是非0值
np.transpose(b) # 求一下转置就比较清楚了
# array([[0, 0],
# [0, 2],
# [1, 1],
# [2, 2]], dtype=int64)
a = np.array([[[0,1],[2,0]],[[0,3],[4,0]],[[0,0],[5,0]]])
b = np.nonzero(a)
np.transpose(b)
# array([[0, 0, 1],
# [0, 1, 0],
# [1, 0, 1],
# [1, 1, 0],
# [2, 1, 0]], dtype=int64)
multiply dot matmul @
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# .multiply
# 数组/矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致 等价于 *
a=np.array([[1,2,3],[4,5,6]]) # 2*3
b=np.array([[4,5,6],[1,2,3]]) # 2*3
np.multiply(a,b)
a * b
# .dot
# 如果参与运算的两个一维数组,那么得到的结果是两个数组的内积
a=np.array([1,2,3]) # (3,)
b=np.array([1,2,3]) # (3,)
np.dot(a,b)
# 如果是二维数组(矩阵)之间的运算,则是矩阵乘法
a=np.array([[1,2,3],[4,5,6]]) # 2*3
b=np.array([[3,4],[4,5],[5,6]]) # 3*2
np.dot(a,b)
# .matmul 矩阵乘法
np.matmul(a,b)
# @ 矩阵乘法
a @ b
np.where
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# np.where(condition, x, y)
# 满足条件(condition),输出x,不满足输出y
a = np.arange(10)
np.where(a, 1, -1)
# array([-1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) # 0为False,所以第一个输出-1
np.where([[True,False], [True,True]],[[1,2], [3,4]],[[9,8], [7,6]])
# array([[1, 8], [3, 4]])
# np.where(condition)
# 输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)
a = np.array([2,4,6,8,10])
np.where(a > 5)
# (array([2, 3, 4]),)
b = np.where([[0, 3], [2, 0]])
# (array([0, 1], dtype=int64), array([1, 0], dtype=int64))
np.transpose(b)
# array([[0, 1],
# [1, 0]], dtype=int64)
np.gradient
1
2
3
4
5
6
7
8
9
# 计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
a = np.random.randint(10, 100, (5, ))
# array([22, 71, 84, 22, 15])
np.gradient(a)
# [ 49. 31. -24.5 -34.5 -7. ]
# 49=71-22, 31=(84-22)/2, -24.5=(22-71)/2...
a = np.random.randint(0, 100, (3, 5))
np.gradient(a) # 两个array 一个是外层的梯度 一个是内层的梯度
matplotlib
1
import matplotlib.pyplot as plt
plt.plot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# plt.plot(x, y, format_string, **kwargs)
plt.plot([1, 3, 2, 6, 5]) # 只有一个参数 相当于y
plt.plot([2, 4, 6, 8, 10], [1, 3, 2, 6, 5]) # x,y (2,1),(4,3)...
a = np.arange(10)
plt.plot(a, a*2, a, a*3, a, a*4) # 多条线
# format_string
# 'b' 蓝色 'm' 洋红色
# 'g' 绿色 'y' 黄色
# 'r' 红色 'k' 黑色
# 'c' 青绿 'w' 白色
# '‐' 实线 '‐‐' 破折线
# '‐.' 点划线 ':' 虚线
# 'o' 实心圆标记 'x' x标记
# '+' +标记 '*' 星形状标记
plt.plot(a, a*2, 'g-.', a, a*3, 'ro', a, a*4, 'b*') # 多条线
plt.subplot
1
2
3
4
5
# 划分区域 指定特定的区域 只是用来选定区域 后边需要配合plt.plot使用
plt.subplot(3, 2, 4) # 3行2列的区域 选择第四块
plt.subplot(324) # 3行2列的区域 选择第四块
plt.plot()
plt.show()
plt.subplots
1
2
3
4
5
6
7
8
9
10
# 默认ax就是整个图
fig, ax = plt.subplots()
ax.plot()
plt.show()
# 划分成2*3的区域 不指定区域 ax.shape=(2,3)
fig, ax = plt.subplots(2, 3)
# 选择第一行第一列的那个区域进行绘图
ax[1,1].plot()
plt.show()
设置各种标识
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
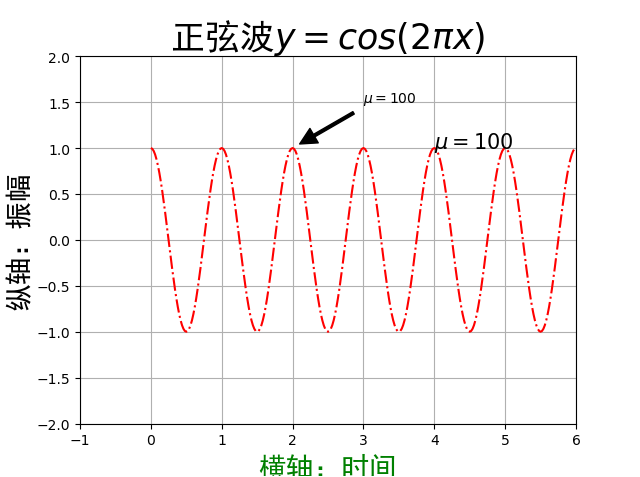
# x轴标题
plt.xlabel('横轴:时间', fontproperties='SimHei', fontsize=20, color='green')
# y轴标题
plt.ylabel('纵轴:振幅', fontproperties='SimHei', fontsize=20)
# 标题
plt.title(r'正弦波$y=cos(2\pi x)$', fontproperties='SimHei', fontsize=25)
# 在任意位置增加文本 这里选择x=4,y=1
plt.text(4, 1, r'$\mu=100$', fontsize=15)
# 添加带箭头的文本 plt.annotate(s, xy=arrow_crd, xytext=text_crd, arrowprops=dict)
plt.annotate(r'$\mu=100$', xy=(2,1), xytext=(3,1.5), arrowprops=dict(facecolor='black', shrink=0.1, width=2))
# 画图 红色点划线
plt.plot(a, np.cos(2*np.pi*a), 'r-.')
# 设置横纵坐标范围
plt.axis([-1, 6, -2, 2])
# 显示网格线
plt.grid(True)
# 保存为test.png 这句话要放最后
plt.savefig('test', dpi=600, bbox_inches='tight') # 设置tight避免显示不全
# 展示图片
plt.show()
# 多条曲线区分可以设置label属性
plot(x, y, color[i], label='type_id=' + str(k))
plt.legend() # 显示标注
plt.show()
# 横坐标过多,只需要显示一部分
span_xticks = 7
plt.xticks(np.array(x)[np.arange(0,len(x),span_xticks)], rotation=30)
# 横坐标文字旋转
plt.xticks(size='small',rotation=80)
# 横轴自动调整 旋转、对齐
plt.gcf().autofmt_xdate()
# 设置字体 这句话要放前边
plt.rc('font',family='Times New Roman',size=11)
绘制其他图表
| 函数 | |
|---|---|
| plt.boxplot(data,notch,position) | 箱形图 |
| plt.bar(left,height,width,bottom) | 条形图 |
| plt.barh(width,bottom,left,height) | 横向条形图 |
| plt.polar(theta, r) | 极坐标图 |
| plt.pie(data, explode) | 饼图 |
| plt.psd(x,NFFT=256,pad_to,Fs) | 功率谱密度图 |
| plt.specgram(x,NFFT=256,pad_to,F) | 谱图 |
| plt.cohere(x,y,NFFT=256,Fs) | X‐Y的相关性函数 |
| plt.scatter(x,y) | 散点图,x和y长度相同 |
| plt.step(x,y,where) | 步阶图 |
| plt.hist(x,bins,normed) | 直方图 |
| plt.contour(X,Y,Z,N) | 等值图 |
| plt.vlines() | 垂直图 |
| plt.stem(x,y,linefmt,markerfmt) | 柴火图 |
| plt.plot_date() | 数据日期 |
1
2
3
4
5
6
7
8
# 散点图
plt.scatter(10*np.random.randn(100), 10*np.random.randn(100), c='b', marker='o')
plt.show()
fig, ax = plt.subplots()
ax.plot(10*np.random.randn(100), 10*np.random.randn(100), 'o')
ax.set_title('scatter')
plt.show()
pandas
1
import pandas as pd
Series
初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
d = pd.Series([10, 12, 1, 20])
# 0 10
# 1 12
# 2 1
# 3 20
# dtype: int64
d.cumsum() # 求前n项和
pd.Series([10, 12, 1, 20], index=['a', 'b', 'c', 'd']) # 自定义索引
# a 10
# b 12
# c 1
# d 20
# dtype: int64
pd.Series(20) # 由标量创建
# 0 20
# dtype: int64
pd.Series(20, index=['a', 'b'])
# a 20
# b 20
# dtype: int64
pd.Series({'a': 9, 'b': 10})
# a 9
# b 10
# dtype: int64
pd.Series({'a': 9, 'b': 10}, index=['a', 'b', 'c'])
# a 9.0
# b 10.0
# c NaN
# dtype: float64
pd.Series(np.arange(4))
# 0 0
# 1 1
# 2 2
# 3 3
# dtype: int32
pd.Series(np.arange(4), index=np.arange(10, 6, -1)) # 索引也可以用ndarray
# 10 0
# 9 1
# 8 2
# 7 3
# dtype: int32
基础操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
d = pd.Series([10, 12, 1, 20], ['a', 'b', 'c', 'd'])
d.index
d.values # ndarray类型
# 索引
d[1] # 12
d['b'] # 12
d[['b', 'a', 'd']] # Series类型
d[:3] # 切片 Series类型
d[d > d.median()] # 筛选
np.exp(d) # e^x
d.get('e', 100) # get不到默认返回100 不会把e补充到d中去
d.get('d', 100) # get到直接返回20
# 运算
a = pd.Series([1, 2, 3], ['a', 'c', 'b'])
b = pd.Series([9, 8, 7, 6], ['a', 'b', 'c', 'd'])
a + b # 相同Index的值相加
# 修改
b['a'] = 15
b['a', 'c'] = 100
Dataframe
初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
pd.DataFrame(np.arange(10).reshape(2, 5))
# 0 1 2 3 4
# 0 0 1 2 3 4
# 1 5 6 7 8 9
dt = {
'one': [1, 2, 3],
'two': [3, 4, 5],
}
pd.DataFrame(dt)
# one two
# 0 1 3
# 1 2 4
# 2 3 5
dt = {
'one': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'e']),
'two': pd.Series([3, 4, 5, 6], index=['a', 'b', 'c', 'd']),
}
pd.DataFrame(dt)
# one two
# a 1.0 3.0
# b 2.0 4.0
# c 3.0 5.0
# d NaN 6.0
# e 4.0 NaN
pd.DataFrame(dt, index=['a', 'c', 'b', 'f'], columns=['three', 'two'])
# 可以单独指定index或者columns
# three two
# a NaN 3.0
# c NaN 5.0
# b NaN 4.0
# f NaN NaN
索引操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
d = pd.DataFrame(dt)
# one two
# a 1.0 3.0
# b 2.0 4.0
# c 3.0 5.0
# d NaN 6.0
# e 4.0 NaN
# 索引
d['one'] # 索引一列
df.one # 索引一列
d.loc['a'] # 索引一行
d[:2] # 前两行 返回的DataFrame
# one two
# a 1.0 3.0
# b 2.0 4.0
d['one']['a'] # 索引一列的一个值
# 改变索引 只是改变了行之间/列之间的顺序
d = d.reindex(columns=['two', 'one'])
# two one
# a 3.0 1.0
# b 4.0 2.0
# c 5.0 3.0
# d 6.0 NaN
# e NaN 4.0
d = d.reindex(index=['e', 'd', 'b', 'c', 'a'])
# two one
# e NaN 4.0
# d 6.0 NaN
# b 4.0 2.0
# c 5.0 3.0
# a 3.0 1.0
d.columns
d.index
添加删除行和列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 添加一列
new = d.columns.insert(4, 'four')
d = d.reindex(columns=new, fill_value=200)
# two one four
# e NaN 4.0 200
# d 6.0 NaN 200
# b 4.0 2.0 200
# c 5.0 3.0 200
# a 3.0 1.0 200
# 添加一列
# 列号,列名,值
d.insert(1, 'name', value)
d.insert(1, 'name', value, allow_duplicates=True) # 允许添加重复的列
# 删除一行
d = d.drop('a') # axis=0 跨行
# two one four
# e NaN 4.0 200
# d 6.0 NaN 200
# b 4.0 2.0 200
# c 5.0 3.0 200
# 删除一列
d = d.drop('one', axis=1)
# two four
# e NaN 200
# d 6.0 200
# b 4.0 200
# c 5.0 200
运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
a = pd.DataFrame(np.arange(12).reshape(3, 4))
b = pd.DataFrame(np.arange(20).reshape(4, 5))
a + b # 形状不一样会出现NAN
a.add(b) # 形状不一样会出现NAN
a.add(b, fill_value=200) # 设置填充数字
a.mul(b, fill_value=0)
# 不同维度运算是广播运算 默认在1轴
c = pd.Series(np.arange(4))
c - 10
b - c # axis=1 每一行-c
b.sub(c, axis=0) # axis=0 每一列-c 跨行
b.sub(c, axis=1) # axis=1 每一行-c
# 不同维度运算是广播运算 默认在1轴
d = pd.DataFrame(np.arange(12, 0, -1).reshape(3, 4))
a > d # 纬度相同
a == d # 纬度相同
a > c # 不同维度 广播运算 默认在1轴 每一行>c
c > 0 # 不同维度 广播运算 默认在1轴
# 其他运算函数
# .sum() 计算数据的总和,按0轴计算,下同 a.sum()
# .count() 非NaN值的数量
# .mean() .median() 计算数据的算术平均值、算术中位数
# .var() .std() 计算数据的方差、标准差
# .min() .max() 计算数据的最小值、最大值
# .argmin() .argmax() 计算数据最大值、最小值所在位置的索引位置(自动索引)
# .idxmin() .idxmax() 计算数据最大值、最小值所在位置的索引(自定义索引)
# .describe() 针对0轴(各列)的统计汇总
# .cumsum() 依次给出前1、2、…、n个数的和
# .cumprod() 依次给出前1、2、…、n个数的积
# .cummax() 依次给出前1、2、…、n个数的最大值
# .cummin() 依次给出前1、2、…、n个数的最小值
# .rolling(w).sum() 依次计算相邻w个元素的和
# .rolling(w).mean() 依次计算相邻w个元素的算术平均值
# .rolling(w).var() 依次计算相邻w个元素的方差
# .rolling(w).std() 依次计算相邻w个元素的标准差
# .rolling(w).min() .max() 依次计算相邻w个元素的最小值和最大值
# .cov() 计算协方差矩阵
# .corr() 计算相关系数矩阵, Pearson、Spearman、Kendall等系数 a.corr(b)
布尔索引
1
2
3
4
5
6
7
8
df = pd.DataFrame(np.random.randn(4, 4), columns=['A', 'B', 'C', 'D'])
df.A > 0
df[df.A > 0] # 布尔索引 选择df.A > 0的行
df['E'] = ['a', 'a', 'c', 'b']
df.E.isin(['a', 'c']) # 判断df.E这一列的每个值在不在['a','c']中
df.isin(['b', 'c']) # 判断df中的每个值在不在['b','c']中
df[df.E.isin(['a', 'c'])] # 布尔索引
排序
1
2
3
4
5
6
7
b = pd.DataFrame(np.arange(20).reshape(4, 5), index=['a', 'c', 'b', 'd'])
# 对索引index排序 结果会交换行的顺序
b.sort_index()
b.sort_index(ascending=False) # 倒序
# 对数据排序 默认axis=0
b.sort_values(2, ascending=False) # 对'2'这一列的值排序,最后导致行的顺序变了 a=0 跨行
b.sort_values('b', axis=1, ascending=False) # 对'b'这一行的值排序,最后导致列的顺序变d了 a=1
读写csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# pd.read_csv
# sep 分隔符,默认','
# delimiter 备选分隔符(如果指定该参数,则sep参数失效)默认为None
# header 指定行数用来作为列名,默认为0。如果文件中没有列名,应该header=None。header=2,列名就是第1行的内容。
# names 设置列名 即df的columns
# index_col 指定用于行索引的列编号或者列名 默认Default,会自动生成一列作为索引;若设置index_col=False代表强制不使用第一列作为行索引
df = pd.read_csv('a.csv', sep='\t')
df = pd.read_csv('a.csv', sep='\t', header=None) # 文件中没有列名
df = pd.read_csv('a.csv', sep='\t', header=0) # 文件中有列名
# df.to_csv
# sep 分隔符,默认','
# na_rep 用于替换空数据的字符串,默认为''
# float_format 格式控制 %.2f
# columns 选择要保存的列
# header 是否保存列名 默认为True
# index 是否保留行索引 默认为True
a.to_csv('a.csv', index=False) # 不保存行索引
df.sample
| 参数名称 | 参数说明 | 举例说明 |
|---|---|---|
| n | 要抽取的行数 | df.sample(n=3,random_state=1) 提取3行数据列表 注意,使用random_state,以确保可重复性的例子。 |
| frac | 抽取行的比例 | 例如frac=0.8,就是抽取其中80%。df.sample(frac=0.8, replace=True, random_state=1) |
| replace | 是否为有放回抽样 | True:有放回抽样,False:未放回抽样 |
| weights | 字符索引或概率数组,axis=0:为行字符索引或概率数组,axis=1:为列字符索引或概率数组 | |
| random_state | int随机数发生器种子,或numpy.random.RandomState | random_state=None,取得数据不重复random_state=1,可以取得重复数据 |
| axis | axis=0:抽取行,axis=1:抽取列 | axis=1时,在列中随机抽取n列。在axis=0时,在行中随机抽取n行。 |
pd.merge
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 按照两个dataframe共有的column进行连接
df1 = pd.DataFrame({'KEY': ['X','Y','Z'], 'VA1': [1,2,3]})
df2 = pd.DataFrame({'KEY': ['X','B','Z'], 'VA2': [4,5,6]})
# 自动按照相同的名字合并
pd.merge(df1, df2)
# KEY VA1 VA2
# 0 X 1 4
# 1 Z 3 6
# on指定用于合并的列名
pd.merge(df1, df2, on='KEY')
# KEY VA1 VA2
# 0 X 1 4
# 1 Z 3 6
# how指定合并的方法 默认innner 取交集
# how=left,df1保留所有的行列数据,df2根据df1的行列进行补全。right同理.outer取并集
pd.merge(df1, df2, on='KEY', how='left')
# KEY VA1 VA2
# 0 X 1 4.0
# 1 Y 2 NaN
# 2 Z 3 6.0
df.join
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 与merge功能类似,区别在于用于索引上的合并
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
left.join(right) # 默认的合并方式how=left
# A B C D
# K0 A0 B0 C0 D0
# K1 A1 B1 NaN NaN
# K2 A2 B2 C2 D2
left.join(right, how='outer') # 并集
# A B C D
# K0 A0 B0 C0 D0
# K1 A1 B1 NaN NaN
# K2 A2 B2 C2 D2
# K3 NaN NaN C3 D3
left.join(right, how='inner') # 交集
# A B C D
# K0 A0 B0 C0 D0
# K2 A2 B2 C2 D2
pd.merge(left, right, left_index=True, right_index=True, how='outer') # merge索引并集
pd.merge(left, right, left_index=True, right_index=True, how='inner') # merge索引交集
pd.concat & df.append
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'E': ['C4', 'C5', 'C6', 'C7'],
'F': ['D4', 'D5', 'D6', 'D7']},
index=[2, 3, 10, 11])
pd.concat([df1,df2]) # 默认axis=0
df.append(df2)
# A B C D E F
# 0 A0 B0 C0 D0 NaN NaN
# 1 A1 B1 C1 D1 NaN NaN
# 2 A2 B2 C2 D2 NaN NaN
# 3 A3 B3 C3 D3 NaN NaN
# 2 A4 B4 NaN NaN C4 D4
# 3 A5 B5 NaN NaN C5 D5
# 10 A6 B6 NaN NaN C6 D6
# 11 A7 B7 NaN NaN C7 D7
pd.concat([df1,df2],join='inner') # 交集 join
pd.concat([df1,df2],join='inner',ignore_index=True) # 重建索引 从0开始排索引值
# A B
# 0 A0 B0
# 1 A1 B1
# 2 A2 B2
# 3 A3 B3
# 4 A4 B4
# 5 A5 B5
# 6 A6 B6
# 7 A7 B7
pd.concat([df1,df2],axis=1,join_axes=[pd.Index([0,2])]) # 索引相同的进行合并 join_axes表明需要留下的索引
# A B C D A B E F
# 0 A0 B0 C0 D0 NaN NaN NaN NaN
# 2 A2 B2 C2 D2 A4 B4 C4 D4
df.groupby
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# 对data1列按照key1进行分组 注意不是key1而是df[key1]
grouped = df['data1'].groupby(df['key1'])
# 取出分组'a'对应的值
grouped.get_group('a')
grouped.mean()
# key1
# a -1.182987
# b 0.808674
# 对data1列按照key1和key2进行分组
df['data1'].groupby([df['key1'], df['key2']]).mean()
# key1 key2
# a one -0.714084
# two -2.120793
# b one 0.642216
# two 0.975133
# 对整个df使用列名进行分组
df.groupby('key1').mean()
# data1 data2
# key1
# a -1.182987 0.062665
# b 0.808674 -0.368333
df.groupby('key1').get_group('a') # 取出a的分组
# key1 key2 data1 data2
# 0 a one -0.677588 0.926943
# 1 a two -0.038206 -0.383044
# 4 a one -1.330092 -0.484162
df.groupby(['key1', 'key2']).mean()
# data1 data2
# key1 key2
# a one -0.714084 -0.005540
# two -2.120793 0.199074
# b one 0.642216 -0.143671
# two 0.975133 -0.592994
df.groupby('key1')['data1'].mean() # 选列
df.groupby(['key1', 'key2'])['data1'].mean() # 选列
# 迭代分组
for name, group in df.groupby('key1'):
print(name)
print(group)
# a
# data1 data2 key1 key2
# 0 -0.410673 0.519378 a one
# 1 -2.120793 0.199074 a two
# 4 -1.017495 -0.530459 a one
# b
# data1 data2 key1 key2
# 2 0.642216 -0.143671 b one
# 3 0.975133 -0.592994 b two
for (k1, k2), group in df.groupby(['key1', 'key2']):
print(k1, k2)
print(group)
# 转换成字典
pieces = dict(list(df.groupby('key1')))
# 分组的键
pieces.keys()
# 分组的值
pieces.values()
# 键值对
origingroup.items()
# 选取行或列 以下形式等价
df.groupby('key1')['data1']
df.groupby(['key1'])['data1']
df['data1'].groupby(df['key1'])
df['data1'].groupby([df['key1']])
df.apply df.applymap series.map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# df.apply 将函数应用到由列或行形成的一维数组上 不改变原dataframe
df=pd.DataFrame(np.arange(20).reshape(4,5),columns=list('abcde'))
# 求每列的最大值与最小值的差
df.apply(lambda x: x.max()-x.min())
# 求每行的最大值与最小值的差
df.apply(lambda x: x.max()-x.min(), axis=1)
# 对某一列操作
df['a'].apply(lambda x: x+10)
# 对某一行操作
df.iloc[0].apply(lambda x: x+10)
# df.applymap 将函数应用到全部元素上 不改变原dataframe
df.applymap(lambda x: 10*x)
# series.map 对Series进行操作 类似于df.apply
df['a'].map(lambda x: x+10)
sklearn
scipy
转载请标明如下内容:
本文作者:姜佳伟
本文链接:https://aptx1231.github.io/2020/09/26/Python%E6%95%B4%E7%90%86/
Github:aptx1231

